Organizations are continuously seeking ways to use their proprietary knowledge and domain expertise to gain a competitive edge. With the advent of foundation models (FMs) and their remarkable natural language processing capabilities, a new opportunity has emerged to unlock the value of their data assets.
As organizations strive to deliver personalized experiences to customers using generative AI, it becomes paramount to specialize the behavior of FMs using their own—and their customers’—data. Retrieval Augmented Generation (RAG) has emerged as a simple yet effective approach to achieve a desired level of specialization.
Amazon Bedrock Knowledge Bases is a fully managed capability that simplifies the management of the entire RAG workflow, empowering organizations to give FMs and agents contextual information from company’s private data sources to deliver more relevant and accurate responses tailored to their specific needs.
For organizations developing multi-tenant products, such as independent software vendors (ISVs) creating software as a service (SaaS) offerings, the ability to personalize experiences for each of their customers (tenants in their SaaS application) is particularly significant. This personalization can be achieved by implementing a RAG approach that selectively uses tenant-specific data.
In this post, we discuss and provide examples of how to achieve personalization using Amazon Bedrock Knowledge Bases. We focus particularly on addressing the multi-tenancy challenges that ISVs face, including data isolation, security, tenant management, and cost management. We focus on scenarios where the RAG architecture is integrated into the ISV application and not directly exposed to tenants. Although the specific implementations presented in this post use Amazon OpenSearch Service as a vector database to store tenants’ data, the challenges and architecture solutions proposed can be extended and tailored to other vector store implementations.
Multi-Tenancy design considerations
When architecting a multi-tenanted RAG system, organizations need to take several considerations into account:
Tenant isolation – One crucial consideration in designing multi-tenanted systems is the level of isolation between the data and resources related to each tenant. These resources include data sources, ingestion pipelines, vector databases, and RAG client application. The level of isolation is typically governed by security, performance, and the scalability requirements of your solution, together with your regulatory requirements. For example, you may need to encrypt the data related to each of your tenants using a different encryption key. You may also need to make sure that high activity generated by one of the tenants doesn’t affect other tenants.
Tenant variability – A similar yet distinct consideration is the level of variability of the features provided to each tenant. In the context of RAG systems, tenants might have varying requirements for data ingestion frequency, document chunking strategy, or vector search configuration.
Tenant management simplicity – Multi-tenant solutions need a mechanism for onboarding and offboarding tenants. This dimension determines the degree of complexity for this process, which might involve provisioning or tearing down tenant-specific infrastructure, such as data sources, ingestion pipelines, vector databases, and RAG client applications. This process could also involve adding or deleting tenant-specific data in its data sources.
Cost-efficiency – The operating costs of a multi-tenant solution depend on the way it provides the isolation mechanism for tenants, so designing a cost-efficient architecture for the solution is crucial.
These four considerations need to be carefully balanced and weighted to suit the needs of the specific solution. In this post, we present a model to simplify the decision-making process. Using the core isolation concepts of silo, pool, and bridge defined in the SaaS Tenant Isolation Strategies whitepaper, we propose three patterns for implementing a multi-tenant RAG solution using Amazon Bedrock Knowledge Bases, Amazon Simple Storage Service (Amazon S3), and OpenSearch Service.
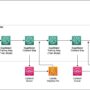
A typical RAG solution using Amazon Bedrock Knowledge Bases is composed of several components, as shown in the following figure:
A data source, such as an S3 bucket
A knowledge base including a data source
A vector database such as an Amazon OpenSearch Serverless collection and index or other supported vector databases
A RAG client application
The main challenge in adapting this architecture for multi-tenancy is determining how to provide isolation between tenants for each of the components. We propose three prescriptive patterns that cater to different use cases and offer carrying levels of isolation, variability, management simplicity, and cost-efficiency. The following figure illustrates the trade-offs between these three architectural patterns in terms of achieving tenant isolation, variability, cost-efficiency, and ease of tenant management.
Multi-tenancy patterns
In this section, we describe the implementation of these three different multi-tenancy patterns in a RAG architecture based on Amazon Bedrock Knowledge Bases, discussing their use cases as well as their pros and cons.
Silo
The silo pattern, illustrated in the following figure, offers the highest level of tenant isolation, because the entire stack is deployed and managed independently for each single tenant.
In the context of the RAG architecture implemented by Amazon Bedrock Knowledge Bases, this pattern prescribes the following:
A separate data source per tenant – In this post, we consider the scenario in which tenant documents to be vectorized are stored in Amazon S3, therefore a separate S3 bucket is provisioned per tenant. This allows for per-tenant AWS Key Management Service (AWS KMS) encryption keys, as well as per-tenant S3 lifecycle policies to manage object expiration, and object versioning policies to maintain multiple versions of objects. Having separate buckets per tenant provides isolation and allows for customized configurations based on tenant requirements.
A separate knowledge base per tenant – This allows for a separate chunking strategy per tenant, and it’s particularly useful if you envision the document basis of your tenants to be different in nature. For example, one of your tenants might have a document base composed of flat text documents, which can be treated with fixed-size chunking, whereas another tenant might have a document base with explicit sections, for which semantic chunking would be better suited to section. Having a different knowledge base per tenant also lets you decide on different embedding models, giving you the possibility to choose different vector dimensions, balancing accuracy, cost, and latency. You can choose a different KMS key per tenant for the transient data stores, which Amazon Bedrock uses for end-to-end per-tenant encryption. You can also choose per-tenant data deletion policies to control whether your vectors are deleted from the vector database when a knowledge base is deleted. Separate knowledge bases also mean that you can have different ingestion schedules per tenants, allowing you to agree to different data freshness standards with your customers.
A separate OpenSearch Serverless collection per tenant – Having a separate OpenSearch Serverless collection per tenant allows you to have a separate KMS encryption key per tenant, maintaining per-tenant end-to-end encryption. For each tenant-specific collection, you can create a separate vector index, therefore choosing for each tenant the distance metric between Euclidean and dot product, so that you can choose how much importance to give to the document length. You can also choose the specific settings for the HNSW algorithm per tenant to control memory consumption, cost, and indexing time. Each vector index, in conjunction with the setup of metadata mappings in your knowledge base, can have a different metadata set per tenant, which can be used to perform filtered searches. Metadata filtering can be used in the silo pattern to restrict the search to a subset of documents with a specific characteristic. For example, one of your tenants might be uploading dated documents and wants to filter documents pertaining to a specific year, whereas another tenant might be uploading documents coming from different company divisions and wants to filter over the documentation of a specific company division.
Because the silo pattern offers tenant architectural independence, onboarding and offboarding a tenant means creating and destroying the RAG stack for that tenant, composed of the S3 bucket, knowledge base, and OpenSearch Serverless collection. You would typically do this using infrastructure as code (IaC). Depending on your application architecture, you may also need to update the log sinks and monitoring systems for each tenant.
Although the silo pattern offers the highest level of tenant isolation, it is also the most expensive to implement, mainly due to creating a separate OpenSearch Serverless collection per tenant for the following reasons:
Minimum capacity charges – Each OpenSearch Serverless collection encrypted with a separate KMS key has a minimum of 2 OpenSearch Compute Units (OCUs) charged hourly. These OCUs are charged independently from usage, meaning that you will incur charges for dormant tenants if you choose to have a separate KMS encryption key per tenant.
Scalability overhead – Each collection separately scales OCUs depending on usage, in steps of 6 GB of memory, and associated vCPUs and fast access storage. This means that resources might not be fully and optimally utilized across tenants.
When choosing the silo pattern, note that a maximum of 100 knowledge bases are supported in each AWS account. This makes the silo pattern favorable for your largest tenants with specific isolation requirements. Having a separate knowledge base per tenant also reduces the impact of quotas on concurrent ingestion jobs (maximum one concurrent job per KB, five per account), job size (100 GB per job), and data sources (maximum of 5 million documents per data source). It also improves the performance fairness as perceived by your tenants. Deleting a knowledge base during offboarding a tenant might be time-consuming, depending on the size of the data sources and the synchronization process. To mitigate this, you can set the data deletion policy in your tenants’ knowledge bases to RETAIN. This way, the knowledge base deletion process will not delete your tenants’ data from the OpenSearch Service index. You can delete the index by deleting the OpenSearch Serverless collection.
Pool
In contrast with the silo pattern, in the pool pattern, illustrated in the following figure, the whole end-to-end RAG architecture is shared by your tenants, making it particularly suitable to accommodate many small tenants.
The pool pattern prescribes the following:
Single data source – The tenants’ data is stored within the same S3 bucket. This implies that the pool model supports a shared KMS key for encryption at rest, not offering the possibility of per-tenant encryption keys. To identify tenant ownership downstream for each document uploaded to Amazon S3, a corresponding JSON metadata file has to be generated and uploaded. The metadata file generation process can be asynchronous, or even batched for multiple files, because Amazon Bedrock Knowledge Bases requires an explicit triggering of the ingestion job. The metadata file must use the same name as its associated source document file, with .metadata.json appended to the end of the file name, and must be stored in the same folder or location as the source file in the S3 bucket. The following code is an example of the format:
{
“metadataAttributes” : {
“tenantId” : “tenant_1”,
…
}
}
In the preceding JSON structure, the key tenantId has been deliberately chosen, and can be changed to a key you want to use to express tenancy. The tenancy field will be used at runtime to filter documents belonging to a specific tenant, therefore the filtering key at runtime must match the metadata key in the JSON used to index the documents. Additionally, you can include other metadata keys to perform further filtering that isn’t based on tenancy. If you don’t upload the object.metadata.json file, the client application won’t be able to find the document using metadata filtering.
Single knowledge base – A single knowledge base is created to handle the data ingestion for your tenants. This means that your tenants will share the same chunking strategy and embedding model, and share the same encryption at-rest KMS key. Moreover, because ingestion jobs are triggered per data source per KB, you will be restricted to offer to your tenants the same data freshness standards.
Single OpenSearch Serverless collection and index – Your tenant data is pooled in a single OpenSearch Service vector index, therefore your tenants share the same KMS encryption key for vector data, and the same HNSW parameters for indexing and query. Because tenant data isn’t physically segregated, it’s crucial that the query client be able to filter results for a single tenant. This can be efficiently achieved using either the Amazon Bedrock Knowledge Bases Retrieve or RetrieveAndGenerate, expressing the tenant filtering condition as part of the retrievalConfiguration (for more details, see Amazon Bedrock Knowledge Bases now supports metadata filtering to improve retrieval accuracy). If you want to restrict the vector search to return results for tenant_1, the following is an example client implementation performing RetrieveAndGenerate based on the AWS SDK for Python (Boto3):
import boto3
bedrock_agent_runtime = boto3.client(
service_name = “bedrock-agent-runtime”
)
tenant_filter = {
“equals”: {
“key”: “tenantId”,
“value”: “tenant_1”
}
}
retrievalConfiguration = {
“vectorSearchConfiguration”: {
“filter”: tenant_filter
}
}
bedrock_agent_runtime.retrieve_and_generate(
input = {
‘text’: ‘The original user query’
},
retrieveAndGenerateConfiguration = {
‘type’: ‘KNOWLEDGE_BASE’,
‘knowledgeBaseConfiguration’: {
‘knowledgeBaseId’: <YOUR_KNOWLEDGEBASE_ID>,
‘modelArn’: <FM_ARN>,
‘retrievalConfiguration’: retrievalConfiguration
}
}
)
text contains the original user query that needs to be answered. Taking into account the document base, <YOUR_KNOWLEDGEBASE_ID> needs to be substituted with the identifier of the knowledge base used to pool your tenants, and <FM_ARN> needs to be substituted with the Amazon Bedrock model Amazon Resource Name (ARN) you want to use to reply to the user query. The client presented in the preceding code has been streamlined to present the tenant filtering functionality. In a production case, we recommend implementing session and error handling, logging and retry logic, and separating the tenant filtering logic from the client invocation to make it inaccessible to developers.
Because the end-to-end architecture is pooled in this pattern, onboarding and offboarding a tenant doesn’t require you to create new physical or logical constructs, and it’s as simple as starting or stopping and uploading specific tenant documents to Amazon S3. This implies that there is no AWS managed API that can be used to offboard and end-to-end forget a specific tenant. To delete the historical documents belonging to a specific tenant, you can just delete the relevant objects in Amazon S3. Typically, customers will have an external application that maintains the list of available tenants and their status, facilitating the onboarding and offboarding process.
Sharing the monitoring system and logging capabilities in this pattern reduces the complexity of operations with a large number of tenants. However, it requires you to collect the tenant-specific metrics from the client side to perform specific tenant attribution.
The pool pattern optimizes the end-to-end cost of your RAG architecture, because sharing OCUs across tenants maximizes the use of each OCU and minimizes the tenants’ idle time. Sharing the same pool of OCUs across tenants means that this pattern doesn’t offer performance isolation at the vector store level, so the largest and most active tenants might impact the experience of other tenants.
When choosing the pool pattern for your RAG architecture, you should be aware that a single ingestion job can ingest or delete a maximum of 100 GB. Additionally, the data source can have a maximum of 5 million documents. If the solution has many tenants that are geographically distributed, consider triggering the ingestion job multiple times a day so you don’t hit the ingestion job size limit. Also, depending on the number and size of your documents to be synchronized, the time for ingestion will be determined by the embedding model invocation rate. For example, consider the following scenario:
Number of tenants to be synchronized = 10
Average number of documents per tenant = 100
Average size per document = 2 MB, containing roughly 200,000 tokens divided in 220 chunks of 1,000 tokens to allow for overlap
Using Amazon Titan Embeddings v2 on demand, allowing for 2,000 RPM and 300,000 TPM
This would result in the following:
Total embeddings requests = 10*100*220 = 220,000
Total tokens to process = 10*100*1,000=1,000,000
Total time taken to embed is dominated by the RPM, therefore 220,000/2,000 = 1 hour, 50 minutes
This means you could trigger an ingestion job 12 times per day to have a good time distribution of data to be ingested. This calculation is a best-case scenario and doesn’t account for the latency introduced by the FM when creating the vector from the chunk. If you expect having to synchronize a large number of tenants at the same time, consider using provisioned throughput to decrease the time it takes to create vector embeddings. This approach will also help distribute the load on the embedding models, limiting throttling of the Amazon Bedrock runtime API calls.
Bridge
The bridge pattern, illustrated in the following figure, strikes a balance between the silo and pool patterns, offering a middle ground that balances tenant data isolation and security.
The bridge pattern delivers the following characteristics:
Separate data source per tenant in a common S3 bucket – Tenant data is stored in the same S3 bucket, but prefixed by a tenant identifier. Although having a different prefix per tenant doesn’t offer the possibility of using per-tenant encryption keys, it does create a logical separation that can be used to segregate data downstream in the knowledge bases.
Separate knowledge base per tenant – This pattern prescribes creating a separate knowledge base per tenant similar to the silo pattern. Therefore, the considerations in the silo pattern apply. Applications built using the bridge pattern usually share query clients across tenants, so they need to identify the specific tenant’s knowledge base to query. They can identify the knowledge base by storing the tenant-to-knowledge base mapping in an external database, which manages tenant-specific configurations. The following example shows how to store this tenant-specific information in an Amazon DynamoDB table:
import boto3
# Create a DynamoDB resource
dynamodb = boto3.resource(‘dynamodb’)
table_name = ‘tenantKbConfig’
attribute_definitions = [
{‘AttributeName’: ‘tenantId’, ‘AttributeType’: ‘S’}
]
key_schema = [
{‘AttributeName’: ‘tenantId’, ‘KeyType’: ‘HASH’}
]
#Create the table holding KB tenant configurations
tenant_kb_config_table = dynamodb.create_table(
TableName=table_name,
AttributeDefinitions=attribute_definitions,
KeySchema=key_schema,
BillingMode=’PAY_PER_REQUEST’ # Use on-demand billing mode for illustration
)
#Create a tenant
tenant_kb_config_table.put_item(
Item={
‘tenantId’: ‘tenant_1’,
‘knowledgebaseId’: <YOUR_KNOWLEDGEBASE_ID>,
‘modelArn’: <FM_ARN> }
)
In a production setting, your application will store tenant-specific parameters belonging to other functionality in your data stores. Depending on your application architecture, you might choose to store knowledgebaseId and modelARN alongside the other tenant-specific parameters, or create a separate data store (for example, the tenantKbConfig table) specifically for your RAG architecture. This mapping can then be used by the client application by invoking the RetrieveAndGenerate API. The following is an example implementation:
import json
import boto3
# Create a DynamoDB resource
dynamodb = boto3.resource(‘dynamodb’)
# Create a Bedrock Runtime client
bedrock_runtime = boto3.client(‘bedrock-agent-runtime’)
# Define the table name
table_name = ‘tenantKbConfig’
# Define function returning tenant config
def get_tenant_config(tenant_id):
table = dynamodb.Table(table_name)
response = table.get_item(
Key = {
‘tenantId’: tenant_id
}
)
if ‘Item’ in response:
return { ‘knowledgebaseId’:response[‘Item’].get(‘knowledgebaseId’), ‘modelArn’: response[‘Item’].get(‘modelArn’)}
else:
return None
# Retrieve the tenant configurations from DynamoDB
tenant_config = get_tenant_config(‘tenant_1’)
#Invoke the Retrieve and Generate API
bedrock_runtime.retrieve_and_generate(
input = {
‘text’: ‘What type of info do your documents contain?’
},
retrieveAndGenerateConfiguration = {
‘type’: ‘KNOWLEDGE_BASE’,
‘knowledgeBaseConfiguration’: {
‘knowledgeBaseId’: tenant_config[‘knowledgebaseId’],
‘modelArn’: tenant_config[‘modelArn’]
}
}
)
Separate OpenSearch Service index per tenant – You store data within the same OpenSearch Serverless collection, but you create a vector index per tenant. This implies your tenants share the same KMS encryption key and the same pool of OCUs, optimizing the OpenSearch Service resources usage for indexing and querying. The separation in vector indexes gives you the flexibility of choosing different HNSM parameters per tenant, letting you tailor the performance of your k-NN indexing and querying for your different tenants.
The bridge pattern supports up to 100 tenants, and onboarding and offboarding a tenant requires the creation and deletion of a knowledge base and OpenSearch Service vector index. To delete the data pertaining to a particular tenant, you can delete the created resources and use the tenant-specific prefix as a logical parameter in your Amazon S3 API calls. Unlike the silo pattern, the bridge pattern doesn’t allow for per-tenant end-to-end encryption; it offers the same level of tenant customization offered by the silo pattern while optimizing costs.
Summary of differences
The following figure and table provide a consolidated view for comparing the characteristics of the different multi-tenant RAG architecture patterns. This comprehensive overview highlights the key attributes and trade-offs associated with the pool, bridge, and silo patterns, enabling informed decision-making based on specific requirements.
The following figure illustrates the mapping of design characteristics to components of the RAG architecture.
The following table summarizes the characteristics of the multi-tenant RAG architecture patterns.
Characteristic
Attribute of
Pool
Bridge
Silo
Per-tenant chunking strategy
Amazon Bedrock Knowledge Base Data Source
No
Yes
Yes
Customer managed key for encryption of transient data and at rest
Amazon Bedrock Knowledge Base Data Source
No
No
Yes
Per-tenant distance measure
Amazon OpenSearch Service Index
No
Yes
Yes
Per-tenant ANN index configuration
Amazon OpenSearch Service Index
No
Yes
Yes
Per-tenant data deletion policies
Amazon Bedrock Knowledge Base Data Source
No
Yes
Yes
Per-tenant vector size
Amazon Bedrock Knowledge Base Data Source
No
Yes
Yes
Tenant performance isolation
Vector database
No
No
Yes
Tenant onboarding and offboarding complexity
Overall solution
Simplest, requires management of new tenants in existing infrastructure
Medium, requires minimal management of end-to-end infrastructure
Hardest, requires management of end-to-end infrastructure
Query client implementation
Original Data Source
Medium, requires dynamic filtering
Hardest, requires external tenant mapping table
Simplest, same as single-tenant implementation
Amazon S3 tenant management complexity
Amazon S3 buckets and objects
Hardest, need to maintain tenant specific metadata files for each object
Medium, each tenant needs a different S3 path
Simplest, each tenant requires a different S3 bucket
Cost
Vector database
Lowest
Medium
Highest
Per-tenant FM used to create vector embeddings
Amazon Bedrock Knowledge Base
No
Yes
Yes
Conclusion
This post explored three distinct patterns for implementing a multi-tenant RAG architecture using Amazon Bedrock Knowledge Bases and OpenSearch Service. The silo, pool, and bridge patterns offer varying levels of tenant isolation, variability, management simplicity, and cost-efficiency, catering to different use cases and requirements. By understanding the trade-offs and considerations associated with each pattern, organizations can make informed decisions and choose the approach that best aligns with their needs.
Get started with Amazon Bedrock Knowledge Bases today.
About the Authors
Emanuele Levi is a Solutions Architect in the Enterprise Software and SaaS team, based in London. Emanuele helps UK customers on their journey to refactor monolithic applications into modern microservices SaaS architectures. Emanuele is mainly interested in event-driven patterns and designs, especially when applied to analytics and AI, where he has expertise in the fraud-detection industry.
Mehran Nikoo is a Generative AI Go-To-Market Specialist at AWS. He leads the generative AI go-to-market strategy for UK and Ireland.
Dani Mitchell is a Generative AI Specialist Solutions Architect at AWS. He is focused on computer vision use case and helps AWS customers in EMEA accelerate their machine learning and generative AI journeys with Amazon SageMaker and Amazon Bedrock.