Data contains information, and information can be used to predict future behaviors, from the buying habits of customers to securities returns. Businesses are seeking a competitive advantage by being able to use the data they hold, apply it to their unique understanding of their business domain, and then generate actionable insights from it. The financial services industry (FSI) is no exception to this, and is a well-established producer and consumer of data and analytics. All industries have their own nuances and ways of doing business, and FSI is no exception—here, considerations such as regulation and zero-sum game competitive pressures loom large. This mostly non-technical post is written for FSI business leader personas such as the chief data officer, chief analytics officer, chief investment officer, head quant, head of research, and head of risk. These personas are faced with making strategic decisions on issues such as infrastructure investment, product roadmap, and competitive approach. The aim of this post is to level-set and inform in a rapidly advancing field, helping to understand competitive differentiators, and formulate an associated business strategy.
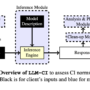
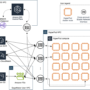
Accelerated computing is a generic term that is often used to refer to specialist hardware called purpose-built accelerators (PBAs). In financial services, nearly every type of activity, from quant research, to fraud prevention, to real-time trading, can benefit from reducing runtime. By performing a calculation more quickly, the user may be able to solve an equation more accurately, provide a better customer experience, or gain an informational edge over a competitor. These activities cover disparate fields such as basic data processing, analytics, and machine learning (ML). And finally, some activities, such as those involved with the latest advances in artificial intelligence (AI), are simply not practically possible, without hardware acceleration. ML is often associated with PBAs, so we start this post with an illustrative figure. The ML paradigm is learning followed by inference. Typically, learning is offline (not streaming real-time data, but historical data) on large volumes of data, whereas inference is online on small volumes of streaming data. Learning means identifying and capturing historical patterns from the data, and inference means mapping a current value to the historical pattern. PBAs, such as graphics processing units (GPUs), have an important role to play in both these phases. The following figure illustrates the idea of a large cluster of GPUs being used for learning, followed by a smaller number for inference. The distinct computational nature of the learning and inference phases means some hardware providers have developed independent solutions for each phase, whereas others have single solutions for both phases.
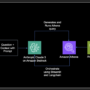
As shown in the preceding figure, the ML paradigm is learning (training) followed by inference. PBAs, such as GPUs, can be used for both these steps. In this example figure, features are extracted from raw historical data, which are then are fed into a neural network (NN). Due to model and data size, learning is distributed over multiple PBAs in an approach called parallelism. Labeled data is used to learn the model structure and weights. Unseen new streaming data is then applied to the model, and an inference (prediction) on that data is made.
This post starts by looking at the background of hardware accelerated computing, followed by reviewing the core technologies in this space. We then consider why and how accelerated computing is important for data processing. Then we review four important FSI use cases for accelerated computing. Key problem statements are identified and potential solutions given. The post finishes by summarizing the three key takeaways, and makes suggestions for actionable next steps.
Background on accelerated computing
CPUs are designed for processing small volumes of sequential data, whereas PBAs are suited for processing large volumes of parallel data. PBAs can perform some functions, such as some floating-point (FP) calculations, more efficiently than is possible by software running on CPUs. This can result in advantages such as reduced latency, increased throughput, and decreased energy consumption. The three types of PBAs are the easily reprogrammable chips such as GPUs, and two types of fixed-function acceleration; field-programmable gate arrays (FPGAs), and application-specific integrated circuits (ASICs). Fixed or semi-fixed function acceleration is practical when no updates are needed to the data processing logic. FPGAs are reprogrammable, albeit not very easily, whereas ASICs are custom designed fully fixed for a specific application, and not reprogrammable. As a general rule, the less user-friendly the speedup, the faster it is. In terms of resulting speedups, the approximate order is programming hardware, then programming against PBA APIs, then programming in an unmanaged language such as C++, then a managed language such as Python. Analysis of publications containing accelerated compute workloads by Zeta-Alpha shows a breakdown of 91.5% GPU PBAs, 4% other PBAs, 4% FPGA, and 0.5% ASICs. This post is focused on the easily reprogrammable PBAs.
The recent history of PBAs begins in 1999, when NVIDIA released its first product expressly marketed as a GPU, designed to accelerate computer graphics and image processing. By 2007, GPUs became more generalized computing devices, with applications across scientific computing and industry. In 2018, other forms of PBAs became available, and by 2020, PBAs were being widely used for parallel problems, such as training of NN. Examples of other PBAs now available include AWS Inferentia and AWS Trainium, Google TPU, and Graphcore IPU. Around this time, industry observers reported NVIDIA’s strategy pivoting from its traditional gaming and graphics focus to moving into scientific computing and data analytics.
The union of advances in hardware and ML has led us to the current day. Work by Hinton et al. in 2012 is now widely referred to as ML’s “Cambrian Explosion.” Although NN had been around since the 1960s and never really worked, Hinton noted three key changes. Firstly, they added more layers to their NN, improving their performance. Secondly, there was a massive increase in the volume of labeled data available for training. Thirdly, the presence of GPUs enabled the labeled data to be processed. Together, these elements lead to the start of a period of dramatic progress in ML, with NN being redubbed deep learning. In 2017, the landmark paper “Attention is all you need” was published, which laid out a new deep learning architecture based on the transformer. In order to train transformer models on internet-scale data, huge quantities of PBAs were needed. In November 2022, ChatGPT was released, a large language model (LLM) that used the transformer architecture, and is widely credited with starting the current generative AI boom.
Review of the technology
In this section, we review different components of the technology.
Parallel computing
Parallel computing refers to carrying out multiple processes simultaneously, and can be categorized according to the granularity at which parallelism is supported by the hardware. For example, a grid of connected instances, multiple processors within a single instance, multiple cores within a single processor, PBAs, or a combination of different approaches. Parallel computing uses these multiple processing elements simultaneously to solve a problem. This is accomplished by breaking the problem into independent parts so that each processing element can complete its part of the workload algorithm simultaneously. Parallelism is suited for workloads that are repetitive, fixed tasks, involving little conditional branching and often large amounts of data. It also means not all workloads are equally suitable for acceleration.
In parallel computing, the granularity of a task is a measure of the amount of communication overhead between the processing functional units. Granularity is typically split into the categories of fine-grained and coarse-grained. Fine-grained parallelism refers to a workload being split into a large number of small tasks, whereas coarse-grained refers to splitting into a small number of large tasks. The key difference between the two categories is the degree of communication and synchronization required between the processing units. A thread of execution is the smallest sequence of programmed instructions that can be managed independently by a scheduler, and is typically a component of a process. The multiple threads of a given process may be run concurrently by multithreading, while sharing resources such as memory. An application can achieve parallelism by using multithreading to split data and tasks into parallel subtasks and let the underlying architecture manage how the threads run, either concurrently on one core or in parallel on multiple cores. Here, each thread performs the same operation on different segments of memory so that they can operate in parallel. This, in turn, enables better system utilization and provides faster program execution.
Purpose built accelerators
Flynn’s taxonomy is a classification of computer architectures helpful in understanding PBAs. Two classifications of relevance are single instruction stream, multiple data streams (SIMD), and the SIMD sub-classification of single instruction, multiple thread (SIMT). SIMD describes computers with multiple processing elements that perform the same operation on multiple data points simultaneously. SIMT describes processors that are able to operate on data vectors and arrays (as opposed to just scalars), and therefore handle big data workloads efficiently. Each SIMT core has multiple threads that run in parallel, thereby giving true simultaneous parallel hardware-level execution. CPUs have a relatively small number of complex cores and are designed to run a sequence of operations (threads) as fast as possible, and can run a few tens of these threads in parallel. GPUs, in contrast, feature smaller cores and are designed to run thousands of threads in parallel in the SIMT paradigm. It is this design that primarily distinguishes GPUs from CPUs and allows GPUs to excel at regular, dense, numerical, data-flow-dominated workloads.
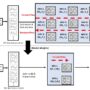
Suppliers of data center GPUs include NVIDIA, AMD, Intel, and others. The AWS P5 EC2 instance type range is based on the NVIDIA H100 chip, which uses the Hopper architecture. The Hopper H100 GPU (SXM5 variant) architecture includes 8 GPU processing clusters (GPCs), 66 texture processing clusters (TPCs), 2 Streaming Multiprocessors (SMs)/TPC, 528 Tensor cores/GPU, and 128 CUDA cores/SM. Additionally, it features 80 GB HBM3 GPU memory, 900 GBps NVLink GPU-to-GPU interconnect, and a 50 MB L2 cache minimizing HBM3 trips. An NVIDIA GPU is assembled in a hierarchal manner: the GPU contains multiple GPCs, and the role of each GPC is to act as a container to hold all the components together. Each GPC has a raster engine for graphics and several TPCs. Inside each TPC is a texture unit, some logic control, and multiple SMs. Inside each SM are multiple CUDA and Tensor cores, and it is here that the compute work happens. The ratio of units GPU:GPC:TPC:SM:CUDA core/Tensor core varies according to release and version. This hierarchal architecture is illustrated in the following figure.
SMs are the fundamental building blocks of an NVIDIA GPU, and consist of CUDA cores, Tensor cores, distributed shared memory, and instructions to support dynamic programming. When a CUDA program is invoked, work is distributed to the multithreaded SMs with available execution capacity. The CUDA core, released in 2007, is a GPU core approximately equal to a CPU core. Although it’s not as powerful as a CPU core, the CUDA core advantage is its ability to be used for large-scale parallel computing. Like a CPU core, each CUDA core still only runs one operation per clock cycle; however, the GPU SIMD architecture enables large numbers of CUDA cores to simultaneously address one data point each. CUDA cores are split into support for different precision, meaning that in the same clock cycle, multiple precision work can be done. The CUDA core is well suited for high-performance computing (HPC) use cases, but is not so well suited for the matrix math found in ML. The Tensor core, released in 2017, is another NVIDIA proprietary GPU core that enables mixed-precision computing, and is designed to support the matrix math of ML. Tensor cores support mixed FP accuracy matrix math in a computationally efficient manner by treating matrices as primitives and being able to perform multiple operations in one clock cycle. This makes GPUs well suited for data-heavy, matrix math-based, ML training workloads, and real-time inference workloads needing synchronicity at scale. Both use cases require the ability to move data around the chip quickly and controllably.
From 2010 onwards, other PBAs have started becoming available to consumers, such as AWS Trainium, Google’s TPU, and Graphcore’s IPU. While an in-depth review on other PBAs is beyond the scope of this post, the core principle is one of designing a chip from the ground up, based around ML-style workloads. Specifically, ML workloads are typified by irregular and sparse data access patterns. This means there is a requirement to support fine-grained parallelism based on irregular computation with aperiodic memory access patterns. Other PBAs tackle this problem statement in a variety of different ways from NVIDIA GPUs, including having cores and supporting architecture complex enough for running completely distinct programs, and decoupling thread data access from the instruction flow by having distributed memory next to the cores.
AWS accelerator hardware
AWS currently offers a range of 68 Amazon Elastic Compute Cloud (Amazon EC2) instance types for accelerated compute. Examples include F1 Xilinx FPGAs, P5 NVIDIA Hopper H100 GPUs, G4ad AMD Radeon Pro V520 GPUs, DL2q Qualcomm AI 100, DL1 Habana Gaudi, Inf2 powered by Inferentia2, and Trn1 powered by Trainium. In March 2024, AWS announced it will offer the new NVIDIA Blackwell platform, featuring the new GB200 Grace Blackwell chip. Each EC2 instance type has a number of variables associated with it, such as price, chip maker, Regional availability, amount of memory, amount of storage, and network bandwidth.
AWS chips are produced by our own Annapurna Labs team, a chip and software designer, which is a wholly owned subsidiary of Amazon. The Inferentia chip became generally available (GA) in December 2019, followed by Trainium GA in October 2022, and Inferentia2 GA in April 2023. In November 2023, AWS announced the next generation Trainium2 chip. By owning the supply and manufacturing chain, AWS is able to offer high-levels of availability of its own chips. Availability AWS Regions are shown in the following table, with more Regions coming soon. Both Inferentia2 and Trainium use the same basic components, but with differing layouts, accounting for the different workloads they are designed to support. Both chips use two NeuronCore-v2 cores each, connected by a variable number of NeuronLink-v2 interconnects. The NeuronCores contain four engines: the first three include a ScalarEngine for scalar calculations, a VectorEngine for vector calculations, and a TensorEngine for matrix calculations. By analogy to an NVIDIA GPU, the first two are comparable to CUDA cores, and the latter is equivalent to TensorCores. And finally, there is a C++ programmable GPSIMD-engine allowing for custom operations. The silicon architecture of the two chips is very similar, meaning that the same software can be used for both, minimizing changes on the user side, and this similarity can be mapped back to their two roles. In general, the learning phase of ML is typically bounded by bandwidth associated with moving large volumes of data to the chip and about the chip. The inference phase of ML is typically bounded by memory, not compute. To maximize absolute-performance and price-performance, Trainium chips have twice as many NeuronLink-v2 interconnects as Inferentia2, and Trainium instances also contain more chips per instance than Inferentia2 instances. All these differences are implemented at the server level. AWS customers such as Databricks and Anthropic use these chips to train and run their ML models.
The following figures illustrate the chip-level schematic for the architectures of Inferentia2 and Trainium.
The following table shows the metadata of three of the largest accelerated compute instances.
Instance Name
GPU Nvidia H100 Chips
Trainium Chips
Inferentia Chips
vCPU Cores
Chip Memory (GiB)
Host Memory (GiB)
Instance Storage (TB)
Instance Bandwidth (Gbps)
EBS Bandwidth (Gbps)
PBA Chip Peer-to-Peer Bandwidth (GBps)
p5.48xlarge
8
0
0
192
640
2048
8 x 3.84 SSD
3,200
80
900 NVSwitch
inf2.48xlarge
0
0
12
192
384
768
EBS only
100
60
192 NeuronLink-v2
trn1n.32xlarge
0
16
0
128
512
512
4 x 1.9 SSD
1,600
80
768 NeuronLink-v2
The following table summarizes performance and cost.
Instance Name
On-Demand Rate ($/hr)
3Yr RI Rate ($/hr)
FP8 TFLOPS
FP16 TFLOPS
FP32 TFLOPS
$/TFLOPS (FP16, theoretical)
Source Reference
p5.48xlarge
98.32
43.18
16,000
8,000
8,000
$5.40
URL
inf2.48xlarge
12.98
5.19
2,280
2,280
570
$2.28
URL
trn1n.32xlarge
24.78
9.29
3,040
3,040
760
$3.06
URL
The following table summarizes Region availability.
Instance Name
Number of AWS Regions Supported In
AWS Regions Supported In
Default Quota Limit
p5.48xlarge
4
us-east-2; us-east-1; us-west-2; eu-north-1
0
inf2.48xlarge
13
us-east-2; us-east-1; us-west-2; ap-south-1; ap-southeast-1; ap-southeast-2; ap-northeast-1; eu-central-1; eu-west-1; eu-west-2; eu-west-3; eu-north-1; sa-east-1;
0
trn1n.32xlarge
3
us-east-2; us-east-1; us-west-2; eu-north-1; ap-northeast-1; ap-south-1; ap-southeast-4
0
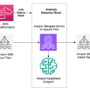
After a user has selected the EC2 instance type, it can then be combined with AWS services designed to support large-scale accelerated computing use cases, including high-bandwidth networking (Elastic Fabric Adapter), virtualization (AWS Nitro Enclaves), hyper-scale clustering (Amazon EC2 UltraClusters), low-latency storage (Amazon FSx for Lustre), and encryption (AWS Key Management Service), while noting not all services are available for all instances in all Regions.
The following figure shows an example of a large-scale deployment of P5 EC2 instances, includes UltraCluster support for 20,000 H100 GPUs, with non-blocking petabit-scale networking, and high-throughput low latency storage. Using the same architecture, UltraCluster supports Trainium scaling to over 60,000 chips.
In summary, we see two general trends in the hardware acceleration space. Firstly, improving price-performance to handle increasing data processing volumes and model sizes, coupled with a need to serve more users, more quickly, and at reduced cost. Secondly, improving security of the associated workloads by preventing unauthorized users from being able to access training data, code, or model weights.
Accelerator software
CPUs and GPUs are designed for different types of workloads. However, CPU workloads can run on GPUs, a process called general-purpose computing on graphics processing units (GPGPU). In order to run a CPU workload on a GPU, the work needs to be reformulated in terms of graphics primitives supported by the GPU. This reformulation can be carried out manually, though it is difficult programming, requiring writing code in a low-level language to map data to graphics, process it, and then map it back. Instead, it is commonly carried out by a GPGPU software framework, allowing the programmer to ignore the underlying graphical concepts, and enabling straightforward coding against the GPU using standard programming languages such as Python. Such frameworks are designed for sequential parallelism against GPUs (or other PBAs) without requiring concurrency or threads. Examples of GPGPU frameworks are the vendor-neutral open source OpenCL and the proprietary NVIDIA CUDA.
For the Amazon PBA chips Inferentia2 and Trainium, the SDK is AWS Neuron. This SDK enables development, profiling, and deployment of workloads onto these PBAs. Neuron has various native integrations to third-party ML frameworks like PyTorch, TensorFlow, and JAX. Additionally, Neuron includes a compiler, runtime driver, as well as debug and profiling utilities. This toolset includes Neuron-top for real-time visualization of the NeuronCore and vCPU utilization, host and device memory usage, and a breakdown of memory allocation. This information is also available in JSON format if neuron-monitor is used, including Neuron-ls for device discovery and topology information. With Neuron, users can use inf2 and trn1n instances with a range of AWS compute services, such as Amazon SageMaker, Amazon Elastic Container Service, Amazon Elastic Kubernetes Service, AWS Batch, and AWS ParallelCluster. This usability, tooling, and integrations of the Neuron SDK has made Amazon PBAs extremely popular with users. For example, over 90% of the top 100 Hugging Face models (now over 100,000 AI models) now run on AWS using Optimum Neuron, enabling the Hugging Face transformer natively supported for Neuron. In summary, the Neuron SDK allows developers to easily parallelize ML algorithms, such as those commonly found in FSI. The following figure illustrates the Neuron software stack.
The CUDA API and SDK were first released by NVIDIA in 2007. CUDA offers high-level parallel programming concepts that can be compiled to the GPU, giving direct access to the GPU’s virtual instruction set and therefore the ability to specify thread-level parallelism. To achieve this, CUDA added one extension to the C language to let users declare functions that could run and compile on the GPU, and a lightweight way to call those functions. The core idea behind CUDA was to remove programmers’ barrier to entry for coding against GPUs by allowing use of existing skills and tools as much as possible, while being more user friendly than OpenCL. The CUDA platform includes drivers, runtime kernels, compilers, libraries, and developer tools. This includes a wide and impressive range of ML libraries like cuDNN and NCCL. The CUDA platform is used through complier directives and extensions to standard languages, such as the Python cuNumeric library. CUDA has continuously optimized over the years, using its proprietary nature to improve performance on NVIDIA hardware relative to vendor-neutral solutions like OpenCL. Over time, the CUDA programming paradigm and stack has become deeply embedded in all aspects of the ML ecosystem, from academia to open source ML repositories.
To date, alternative GPU platforms to CUDA have not seen widespread adoption. There are three key reasons for this. Firstly, CUDA has had a decades-long head start, and benefits from the networking effect of its mature ecosystem, from organizational inertia of change, and from risk aversion to change. Secondly, migrating CUDA code to a different GPU platform can be technically difficult, given the complexity of the ML models typically being accelerated. Thirdly, CUDA has integrations with major third-party ML libraries, such as TensorFlow and PyTorch.
Despite the central role CUDA plays in the AI/ML community, there is movement by users to diversify their accelerated workflows by movement towards a Pythonic programming layer to make training more open. A number of such efforts are underway, including projects like Triton and OneAPI, and cloud service features such as Amazon SageMaker Neo. Triton is an open source project lead by OpenAI that enables developers to use different acceleration hardware using entirely open source code. Triton uses an intermediate compiler to convert models written in supported frameworks into an intermediate representation that can then be lowered into highly optimized code for PBAs. Triton is therefore a hardware-agnostic convergence layer that hides chip differences.
Soon to be released is the AWS neuron kernel interface (NKI) programming interface. NKI is a Python-based programming environment designed for the compiler, which adopts commonly used Triton-like syntax and tile-level semantics. NKI provides customization capabilities to fully optimize performance by enabling users to write custom kernels, by passing almost all of the AWS compiler layers.
OneAPI is an open source project lead by Intel for a unified API across different accelerators including GPUs, other PBAs, and FPGAs. Intel believes that future competition in this space will happen for inference, unlike in the learning phase, where there is no software dependency. To this end, OneAPI toolkits support CUDA code migration, analysis, and debug tools. Other efforts are building on top of OneAPI; for, example the Unified Acceleration Foundation’s (UXL) goal is a new open standard accelerator software ecosystem. UXL consortium members include Intel, Google, and ARM.
Amazon SageMaker is an AWS service providing an ML development environment, where the user can select chip type from the service’s fleet of Intel, AMD, NVIDIA, and AWS hardware, offering varied cost-performance-accuracy trade-offs. Amazon contributes to Apache TVM, an open source ML compiler framework for GPUs and PBAs, enabling computations on any hardware backend. SageMaker Neo uses Apache TVM to perform static optimizations on trained models for inference for any given hardware target. Looking to the future, the accelerator software field is likely to evolve; however, this may be slow to happen.
Accelerator supply-demand imbalances
It has been widely reported for the last few years that GPUs are in short supply. Such shortages have led to industry leaders speaking out. For example, Sam Altman said “We’re so short on GPUs the less people use our products the better… we don’t have enough GPUs,” and Elon Musk said “It seems like everyone and their dog is buying GPUs at this point.”
The factors leading to this have been high demand coupled with low supply. High demand has risen from a range of sectors, including crypto mining, gaming, generic data processing, and AI. Omdia Research estimates 49% of GPUs go to the hyper-clouds (such as AWS or Azure), 27% go to big tech (such as Meta and Tesla), 20% go to GPU clouds (such as Coreweave and Lambda) and 6% go to other companies (such as OpenAI and FSI firms). The State of AI Report gives the size and owners of the largest A100 clusters, the top few being Meta with 21,400, Tesla with 16,000, XTX with 10,000, and Stability AI with 5,408. GPU supply has been limited by factors including lack of manufacturing competition and ability at all levels in the supply chain, and restricted supply of base components such as rare metals and circuit boards. Additionally, rate of manufacturing is slow, with an H100 taking 6 months to make. Socio-political events have also caused delays and issues, such as a COVID backlog, and with inert gases for manufacturing coming from Russia. A final issue impacting supply is that chip makers strategically allocate their supply to meet their long-term business objectives, which may not always align with end-users’ needs.
Supported workloads
In order to benefit from hardware acceleration, a workload needs to be parallelizable. An entire branch of science is dedicated to parallelizable problems. In The Landscape of Parallel Computing Research, 13 fields (termed dwarfs) are found to be fundamentally parallelizable, including dense and sparse linear algebra, Monte Carlo methods, and graphical models. The authors also call out a series of fields they term “embarrassingly sequential” for which the opposite holds. In FSI, one of the main data structures dealt with is time series, a series of sequential observations. Many time series algorithms have the property where each subsequent observation is dependent on previous observations. This means only some time series workloads can be efficiently computed in parallel. For example, a moving average is a good example of a computation that seems inherently sequential, but for which there is an efficient parallel algorithm. Sequential models, such as Recurrent Neural Networks (RNN) and Neural Ordinary Differential Equations, also have parallel implementations. In FSI, non-time series workloads are also underpinned by algorithms that can be parallelized. For example, Markovitz portfolio optimization requires the computationally intensive inversion of large covariance matrices, for which GPU implementations exist.
In computer science, a number can be represented with different levels of precision, such as double precision (FP64), single precision (FP32), and half-precision (FP16). Different chips support different representations, and different representations are suitable for different use cases. The lower the precision, the less storage is required, and the faster the number is to process for a given amount of computational power. FP64 is used in HPC fields, such as the natural sciences and financial modeling, resulting in minimal rounding errors. FP32 provides a balance between accuracy and speed, is used in applications such as graphics, and is the standard for GPUs. FP16 is used in deep learning where computational speed is valued, and the lower precision won’t drastically affect the model’s performance. More recently, other number representations have been developed which aim to improve the balance between acceleration and precision, such as OCP Standard FP8, Google BFloat16, and Posits. An example of a mixed representation use case is the updating of model parameters by gradient decent, part of the backpropagation algorithm, as used in deep learning. Typically this is done using FP32 to reduce rounding errors, however, in order to reduce memory load, the parameters and gradients can be stored in FP16, meaning there is a conversion requirement. In this case, BFloat16 is a good choice because it prevents float overflow errors while keeping enough precision for the algorithm to work.
As lower-precision workloads become more important, hardware and infrastructure trends are changing accordingly. For example, comparing the latest NVIDIA GB200 chip against the previous generation NVIDIA H100 chip, lower representation FP8 performance has increased 505%, but FP64 performance has only increased 265%. Likewise, in the forthcoming Trainium2 chip, the focus has been on lower-bit performance increases, giving a 400% performance increase over the previous generation. Looking to the future, we might expect to see a convergence between HPC and AI workloads, as AI starts to become increasingly important in solving what were traditionally HPC FP64 precision problems.
Accelerator benchmarking
When considering compute services, users benchmark measures such as price-performance, absolute performance, availability, latency, and throughput. Price-performance means how much compute can be done for $1, or what is the equivalent dollar cost for a given number of FP operations. For a perfect system, the price-performance ratio increases linearly as the size of a job scales up. A complicating factor when benchmarking compute grids on AWS is that EC2 instances come in a range of system parameters and a grid might contain more than one instance type, therefore systems are benchmarked at the grid level rather than on a more granular basis. Users often want to complete a job as quickly as possible and at the lowest cost; the constituent details of the system that achieves this aren’t as important.
A second benchmarking measure is absolute-performance, meaning how quickly can a given job be completed independent of price. Given linear scaling, job completion time can be reduced by simply adding more compute. However, it might be that the job isn’t infinitely divisible, and that only a single computational unit is required. In this case, the absolute performance of that computational unit is important. In an earlier section, we provided a table with one performance measure, the $/TFLOP ratio based on the chip specifications. However, as a rule of thumb, when such theoretical values are compared against experimental values, only around 45% is realized.
There are a few different ways to calculate price-performance. The first is to use a standard benchmark, such as LINPACK, HPL-MxP, or MFU (Model FLOPS Utilization). These can run a wide range of calculations that are representative of varying use cases, such as general use, HPC, and mixed HPC and AI workloads. From this, the TFLOP/s at a given FP precision for the system can be measured, along with the dollar-cost of running the system. However, it might be that the user has specific use cases in mind. In this case, the best data will come from price-performance data on a more representative benchmark.
There are various types of representative benchmark commonly seen. Firstly, the user can use real production data and applications with the hardware being benchmarked. This option gives the most reliable results, but can be difficult to achieve due to operational and compliance hurdles. Secondly, the user can replicate their existing use case with a synthetic data generator, avoiding the challenges of getting production data into new test systems. Thirdly, the use can employ a third-party benchmark for the use case, if one exists. For example, STAC is a company that coordinates an FSI community called the STAC Benchmark Council, which maintain a selection of accelerator benchmarks, including A2, A3, ML and AI (LLM). A2 is designed for compute-intensive analytic workloads involved in pricing and risk management. Specifically, the A2 workload uses option price discovery by Monte Carlo estimation of Heston-based Greeks for a path-dependent, multi-asset option with early exercise. STAC members can access A2 benchmarking reports, for example EC2 c5.metal, with the oneAPI. STAC-ML benchmarks the latency of NN inference—the time from receiving new input data until the model output is computed. STAC-A3 benchmarks the backtesting of trading algorithms to determine how strategies would have performed on historical data. This benchmark supports accelerator parallelism to run many backtesting experiments simultaneously, for the same security. For each benchmark, there exists a series of software packages (termed STAC Packs), which are accelerator-API specific. For some of the preceding benchmarks, STAC Packs are maintained by providers such as NVIDIA (CUDA) and Intel (oneAPI).
Some FSI market participants are performing in-house benchmarking at the microarchitecture level, in order to optimize performance as far as possible. Citadel has published microbenchmarks for NVIDIA GPU chips, dissecting the microarchitecture to achieve “bare-metal performance tuning,” noting that peak performance is inaccessible to software written in plain CUDA. Jane Street has looked at performance optimization through functional programming techniques, while PDT Partners has supported work on the Nixpkgs repository of ML packages using CUDA.
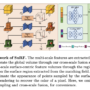
Some AWS customers have benchmarked the AWS PBAs against other EC2 instance types. ByteDance, the technology company that runs the video-sharing app TikTok, benchmarked Inf1 against a comparable EC2 GPU instance type. With Inf1, they were able to reduce their inference latency by 25%, and costs by 65%. In a second example, Inf2 is benchmarked against a comparable inference-optimized EC2 instance. The benchmark used is the RoBERTa-Base, a popular model used in natural language processing (NLP) applications, that uses the transformer architecture. In the following figure, on the x-axis we plotted throughput (the number of inferences that are completed in a set period of time), and on the y-axis we plotted latency (the time it takes the deep learning model to provide an output). The figure shows that Inf2 gives higher throughput and lower latency than the comparable EC2 instance type.
In a third benchmark example, Hugging Face benchmarked the trn1.32xlarge instance (16 Trainium chips) and two comparable EC2 instance types. For the first instance type, they ran fine-tuning for the BERT Large model on the full Yelp review dataset, using the BF16 data format with the maximum sequence length supported by the model (512). The benchmark results show the Trainium job is five times faster while being only 30% more expensive, resulting in a “huge improvement in cost-performance.” For the latter instance type, they ran three tests: language pretraining with GPT2, token classification with BERT Large, and image classification with the Vision Transformer. These results showed trn1 to be 2–5 times faster and 3–8 times cheaper than the comparable EC2 instance types.
FSI use cases
As with other industry sectors, there are two reasons why FSI uses acceleration. The first is to get a fixed result in the lowest time possible, for example parsing a dataset. The second is to get the best result in a fixed time, for example overnight parameter re-estimation. Use cases for acceleration exist across the FSI, including banking, capital markets, insurance, and payments. However, the most pressing demand comes from capital markets, because acceleration speeds up workloads and time is one of the easiest edges people can get in the financial markets. Put differently, a time advantage in financial services often equates to an informational advantage.
We begin by providing some definitions:
Parsing is the process of converting between data formats
Analytics is data processing using either deterministic or simple statistical methods
ML is the science of learning models from data, using a variety of different methods, and then making decisions and predictions
AI is an application able to solve problems using ML
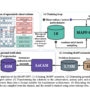
In this section, we review some of the FSI use cases of PBAs. As many FSI activities can be parallelized, most of what is done in FSI can be sped up with PBAs. This includes most modeling, simulations, and optimization problems— currently in FSI, deep learning is only a small part of the landscape. We identify four classes of FSI use cases and look at applications in each class: parsing financial data, analytics on financial data, ML on financial data, and low-latency applications. To try and show how these classes relate to each other, the following figure shows a simplified representation of a typical capital market’s workflow. In this figure, acceleration categories have been assigned to the workflow steps. However, in reality, every step in the process may be able to benefit from one or more of the defined acceleration categories.
Parsing
A typical capital markets workflow consists of receiving data and then parsing it into a useable form. This data is commonly market data, as output from a trading venue’s matching engine, or onward from a market data vendor. Market participants who are receiving either live or historical data feeds need to ingest this data and perform one or more steps, such as parse the message out of a binary protocol, rebuild the limit order book (LOB), or combine multiple feeds into a single normalized format. Any of these parsing steps that run in parallel could be sped up relative to sequential processing. To give an idea of scale, the largest financial data feed is the consolidated US equity options feed, termed OPRA. This feed comes from 18 different trading venues, with 1.5 million contracts broadcast across 96 channels, with a supported peak message rate of 400 billion messages per day, equating to approximately 12 TB per day, or 3 PB per year. As well as maintaining real-time feeds, participants need to maintain a historical depositary, sometimes of several years in size. Processing of historical repositories is done offline, but is often a source of major cost. Overall, a large consumer of market data, such as an investment bank, might consume 200 feeds from across public and private trading venues, vendors, and redistributors.
Any point in this data processing pipeline that can be parallelized, can potentially be sped up by acceleration. For example:
Trading venues broadcast on channels, which can be groupings of alphabetical tickers or products.
On a given channel, different tickers update messages are broadcast sequentially. These can then be parsed out into unique streams per ticker.
For a given LOB, some events might be applicable to individual price levels independently.
Historical data is normally (but not always) independent inter-day, meaning that days can be parsed independently.
In GPU Accelerated Data Preparation for Limit Order Book Modeling, the authors describe a GPU pipeline handling data collection, LOB pre-processing, data normalization, and batching into training samples. The authors note their LOB pre-processing relies on the previous LOB state, and must be done sequentially. For LOB building, FPGAs seem to be used more commonly than GPUs because of the fixed nature of the workload; see examples from Xilinx and Algo-Logic. For example code for a build lab, using the AWS FPGA F1 instance type, refer to the following GitHub repo.
An important part of the data pipeline is the production of features, both online and offline. Features (also called alphas, signals, or predictors) are statistical representations of the data, which can then be used in downstream model building. A current trend in the FSI prediction space is the large-scale automation of dataset ingestion, curation, processing, feature extraction, feature combination, and model building. An example of this approach is given by WorldQuant, an algorithmic trading firm. The WSJ reports “a data group scours the globe for interesting and new data sets, including everything from detailed market pricing data to shipping statistics to footfall in stores captured by apps on smartphones”. WorldQuant states “in 2007 we had two data sets—today [2022] we have more than 1,400.” The general idea being if they could buy, consume, create, and web scrape more data than anyone else, they could create more alphas, and find more opportunities. Such an approach is based on performance being proportional to √N, where N is the number of alphas. Therefore, as long as an alpha is not perfectly correlated with another, there is value in adding it to the set. In 2010, WorldQuant was producing several thousand alphas per year, by 2016 had one million alphas, by 2022, had multiple millions, with a stated ambition to get to 100 million alphas. Although traditional quant finance mandates the importance of an economic rationale behind an alpha, the data-driven approach is led purely by the patterns in the data. After alphas have been produced, they can be intelligently merged together in a time-variant manner. Examples of signal combination methodologies which can benefit from PBA speed-up include Mean Variance Optimization and Bayesian Model Averaging. The same WSJ article states “No one alpha is important. Our edge is putting things together, it’s the implementation…. The idea is that with so many ‘alphas,’ even weak signals can be useful. If counting cars in parking lots next to big box retailers has only a tiny predictive power for those retailers’ stock prices, it can still be used to enhance a bigger prediction if combined with other weak signals. For example, an uptick in cars at Walmart parking lots—itself a relatively weak signal—could combine with similar trends captured by mobile phone apps and credit-card receipts harvested by companies that scan emails to create a more reliable prediction.” The automated process of data ingestion, processing, packaging, combination, and prediction is referred to by WorldQuant as their “alpha factory.”
From examples such as those we’ve discussed, it seems clear that parallelization, speed-up and scale-up, of such huge data pipelines is potentially an important differentiator. All the way through this pipeline, activities could be accelerated using PBAs. For example, for use at the signal combination phase, the Shapley value is a metric that can be used to compute the contribution of a given feature to a prediction. Shapley value computation has PBA-acceleration support in the Python XGBoost library.
Analytics
In this section, we consider the applicability of accelerator parallelism to analytics workloads. One of the parallelizable dwarfs is Monte Carlo, and for FSI and time series work in general, this is an important method. Monte Carlo is a way to compute expected values by generating random scenarios and then averaging them. By using GPUs, a simulated path can be assigned to each thread, allowing simulation of thousands of paths in parallel.
Post the 2008 credit crunch, new regulations require banks to run credit valuation adjustment (CVA) calculations every 24 hours. CVA is an adjustment to a derivatives price as charged by a bank to a counterparty. CVA is one of a family of related valuation adjustments collectively known as xVA, which include debt valuation adjustment (DVA), initial margin valuation adjustment (MVA), capital valuation adjustment (KVA), and funding valuation adjustment (FVA). Because this adjustment calculation can happen over large portfolios of complex, non-linear instruments, closed-form analytical solutions aren’t possible, and as such an empirical approximation by a technique such as Monte Carlo is required. The downside of Monte Carlo here is how computationally demanding it is, due to the size of the search space. The advent of this new regulation coincided with the coming of age of GPUs, and as such banks commonly use GPU grids to run their xVA calculations. In XVA principles, nested Monte Carlo strategies, and GPU optimizations, the authors find a nested simulation time of about an hour for a billion scenarios on the bank portfolio, and a GPU speedup of 100 times faster relative to CPUs. Rather than develop xVA applications internally, banks often use third-party independent software vendor (ISV) solutions to run their xVA calculations, such as Murex M3 or S&P Global XVA. Banking customers can choose to run such ISV software as a service (SaaS) solutions inside their own AWS accounts, and often on AWS accelerated instances.
A second use of PBAs in FSI Monte Carlo is in option pricing, especially for exotic options whose payoff is sometimes too complex to solve in closed-form. The core idea is using a random number generator (RNG) to simulate the stochastic components in a formula and then average the results, leading to the expected value. The more paths that are simulated, the more accurate the result is. In Quasi-Monte Carlo methods for calculating derivatives sensitivities on the GPU, the authors find 200-times greater speedup over CPUs, and additionally develop a number of refinements to reduce variance, leading to fewer paths needing to be simulated. In High Performance Financial Simulation Using Randomized Quasi-Monte Carlo Methods, the authors survey quasi Monte Carlo sequences in GPU libraries and review commercial software tools to help migrate Monte Carlo pricing models to GPU. In GPU Computing in Bayesian Inference of Realized Stochastic Volatility Model, the author computes a volatility measure using Hybrid Monte Carlo (HMC) applied to realized stochastic volatility (RSV), parallelized on a GPU, resulting in a 17-times faster speedup. Finally, in Derivatives Sensitivities Computation under Heston Model on GPU, the authors achieve a 200-times faster speedup; however, the accuracy of the GPU method is inferior for some Greeks relative to CPU.
A third use of PBAs in FSI Monte Carlo is in LOB simulations. We can categorize different types of LOB simulations: replay of the public historical data, replay of the mapped public-private historical data, replay of synthetic LOB data, and replay of a mix of historical and synthetic data to simulate the effects of a feedback loop. For each of these types of simulation, there are multiple ways in which hardware acceleration could occur. For example, for the simple replay case, each accelerator thread could have a different LOB. For the synthetic data case, each thread could have a different version of the same LOB, thereby allowing multiple realizations of a single LOB. In Limit Order Book Simulations: A Review, the authors provide their own simulator classification scheme based on the mathematical modeling technique used—point processes, agent based, deep learning, stochastic differential equations. In JAX-LOB: A GPU-Accelerated limit order book simulator to unlock large scale reinforcement learning for trading, the authors use GPU accelerated training, processing thousands of LOBs in parallel, giving a “notably reduced per message processing time.”
Machine learning
Generative AI is the most topical ML application at this point in time. Generative AI has four main applications: classification, prediction, understanding, and data generation, which in turn map to use cases such as customer experience, knowledge worker productivity, surfacing information and sentiment, and innovation and automation. FSI examples exist for all of these; however, a thorough review of these is beyond the scope of this post. For this post, we remain focused on PBA applicability and look at two of these topics: chatbots and time series prediction.
The 2017, the publication of the paper Attention is all you need resulted in a new wave of interest in ML. The transformer architecture presented in this paper allowed for a highly parallelizable network structure, meaning more data could be processed than before, allowing patterns to be better captured. This has driven impressive real-world performance, as seen by popular public foundation models (FMs) such as OpenAI ChatGPT, and Anthropic Claude. These factors in turn have driven new demand for PBAs for training and inference on these models.
FMs, also termed LLMs, or chatbots when text focused, are models that are typically trained on a broad spectrum of generalized and unlabeled data and are capable of performing a wide variety of general tasks in FSI, such as the Bridgewater Associates LLM-powered Investment Analyst Assistant, which generates charts, computes financial indicators, and summarizes results. FSI LLMs are reviewed in Large Language Models in Finance: A Survey and A Survey of Large Language Models for Financial Applications: Progress, Prospects and Challenges. FMs are often used as base models for developing more specialized downstream applications.
PBAs are used in three different types of FM training. Firstly, to train a FM from scratch. In BloombergGPT: A Large Language Model for Finance, the training dataset was 51% financial data from their systems and 49% public data, such as Wikipedia and Pile. SageMaker was used to train and evaluate their FM. Specifically, 64 p4d.24xlarge instances, giving a total of 512 A100 GPUs. Also used was SageMaker model parallelism, enabling the automatic distribution of the large model across multiple GPU devices and instances. The authors started with a compute budget of 1.3 million GPU hours, and noted training took approximately 53 days.
The second training approach is to fine-tune an existing FM. This requires using an FM whose model parameters are exposed, and updating them in light of new data. This approach can be effective when the data corpus differs significantly from the FM training data. Fine-tuning is cheaper and quicker than training FM from scratch, because the volume of data is likely to be much smaller. As with the larger-scale training from scratch, fine-tuning benefits significantly from hardware acceleration. In an FSI example, Efficient Continual Pre-training for Building Domain Specific Large Language Models, the authors fine-tune an FM and find that their approach outperforms standard continual pre-training performance with just 10% of the corpus size and cost, without any degradation on open-domain standard tasks.
The third training approach is to perform Retrieval Augmented Generation (RAG). To equip FMs with up-to-date and proprietary information, organizations use RAG, a technique that fetches data from company data sources and enriches the prompt to provide more relevant and accurate responses. The two-step workflow consists of ingesting data and vectorizing data, followed by runtime orchestration. Although hardware acceleration is less common in RAG applications, latency of search is a key component and as such the inference step of RAG can be hardware optimized. For example, the performance of OpenSearch, a vectorized database available on AWS, can be improved by using PBAs, with both NVIDIA GPUs and Inferentia being supported.
For these three training approaches, the role of PBAs varies. For processing the huge data volumes of FM building, PBAs are essential. Then, as the training volumes reduce, so does the value-add role of the PBA. Independent of how the model has been trained, PBAs have a key role in LLM inference, again because they are optimized for memory bandwidth and parallelism. The specifics of how to optimally use an accelerator depend on the use case—for example, a paid-for-service chatbot might be latency sensitive, whereas for a free version, a delay of a few milliseconds might be acceptable. If a delay is acceptable, then batching the queries together could help make sure a given chip’s processes are saturated, giving better dollar usage of the resource. Dollar costs are particularly importance in inference, because unlike training, which is a one-time cost, inference is a reoccurring cost.
Using ML for financial time series prediction is nothing new; a large body of public research exists on these methods and applications dating to the 1970s and beyond—for approximately the last decade, PBAs have been applied to this field. As discussed earlier, most ML approaches can be accelerated with hardware; however, the attention-based architecture using the transformer model is currently the most topical. We consider three areas of FSI application: time series FMs, NN for securities prediction, and reinforcement learning (RL).
The initial work on LLMs was conducted on text-based models. This was followed by multi-modal models, able to handle images and other data structures. Subsequent to this, publications have started to appear on time series FMs, including Amazon Chronos, Nixtla TimeGEN-1, and Google TimesFM. The behavior of the time series models appears to be similar to that of the language models. For example, in Scaling-laws for Large Time-series Models, the authors observe the models follow the same scaling laws. A review of these models is provided in Foundation Models for Time Series Analysis: A Tutorial and Survey. As with leading LLMs, time series FMs are likely to be successfully trained on large clusters of PBAs. In terms of size, GPT-3 was trained on a cluster of 10,000 V100s. The size of the GPT-4 training cluster is not public, but is speculated to have been trained on a cluster of 10,000–25,000 A100s. This is analogous in size to one algorithmic trading firm’s statement, “our dedicated research cluster contains … 25,000 A/V100 GPUs (and growing fast).”
Looking to the future, one possible outcome might be that time series FMs, trained at huge expense by a few large corporates, become the base models for all financial prediction. Financial services firms then modify these FMs through additional training with private data or their own insights. Examples of private labeled data might be knowledge of which orders and executions in the public feed belonged to them, or similarly which (meta)orders and executions had parent-child relationships.
Although such financial time series FMs trained on PBA clusters may offer enhanced predictive capabilities, they also bring risks. For example, the EU’s AI act, adopted in March 2024, states that if a model has been trained with a total compute power in excess of 1025 FLOPs, then that model is considered to pose “systemic risk” and is subject to enhanced regulation, including fines of 3% of global turnover, so on this basis Meta announced in June 2024 they will not be enabling some models inside Europe. This legislation assumes that training compute is a direct proxy for model capabilities. EpochAI provides an analysis of the training compute required for a wide range of FMs; for example, GPT-4 took 2.125 FLOPS to train (exceeding the threshold by a factor of 2.1), whereas BloombergGPT took 2.423 FLOPS (under the threshold by a factor of 0.02). It seems possible that in the future, similar legislation may apply to financial FMs, or even to the PBA clusters themselves, with some market participants choosing not to operate in legislative regimes that are subject to such risks.
Feature engineering plays a key role in building NN models, because features are fed into the NN model. As seen earlier in this post, some participants have generated large numbers of features. Examples of features derived from market time series data include bid-ask spreads, weighted mid-points, imbalance measures, decompositions, liquidity predictions, trends, change-points, and mean-reversions. Together, the features are called the feature space. A transformer assigns more importance to part of the input feature space, even though it might only be a small part of the data. Learning which part of the data is more important than another depends on the context of the features. The true power of FMs in time series prediction is the ability to capture these conditional probabilities (the context) across the feature space. To give a simple example, based on historical data, trends might reduce in strength as they go on, leading to a change-point, and then reversion to the mean. A transformer potentially offers the ability to recognize this pattern and capture the relationship between the features more accurately than other approaches. An informative visualization of this for the textual case is given by the FT article Generative AI exists because of the transformer. In order to build and train such FMs on PBAs, access to high-quality historical data tightly coupled with scalable compute to generate the features is an essential prerequisite.
Prior to the advent of the transformer, NN have historically been applied to securities prediction with varying degrees of success. Deep Learning for Limit Order Books uses a cluster of 50 GPUs to predict the sign of the future return by mapping the price levels of the LOB to the visible input layer of a NN, resulting in a trinomial output layer. Conditional on the return the sign, the magnitude of the return is estimated using regression. Deep Learning Financial Market Data uses raw LOB data pre-processed into discrete, fixed-length features for training a recurrent autoencoder, whose recurrent structure allows learning patterns on different time scales. Inference occurs by generating the decoded LOB, and nearest-matching that to the real-time data.
In Multi-Horizon Forecasting for Limit Order Books: Novel Deep Learning Approaches and Hardware Acceleration using Intelligent Processing Units, the authors benchmark the performance of Graphcore IPUs against an NVIDIA GPU on an encoder-decoder NN model. Given that encoder-decoder models rely on recurrent neural layers, they generally suffer from slow training processes. The authors address this by finding that the IPU offers a significant training speedup over the GPU, 694% on average, analogous to the speedup a transformer architecture would provide. In some examples of post-transformer work in this space, Generative AI for End-to-End Limit Order Book Modelling and A Generative Model Of A Limit Order Book Using Recurrent Neural Networks have trained LLM analogues on historical LOB data, interpreting each LOB event (such as insertions, cancellations, and executions) as a word and predicting the series of events following a given word history. However, the authors find the prediction horizon for LOB dynamics appears to be limited to a few tens of events, possibly because of the high-dimensionality of the problem and the presence of long-range correlations in order sign. These results have been improved in the work “Microstructure Modes” — Disentangling the Joint Dynamics of Prices & Order Flow, by down-sampling the data and reducing its dimensionality, allowing identification of stable components.
RL is an ML technique where an algorithm interacts with a dynamic environment that provides feedback to the algorithm, allowing the algorithm to iteratively optimize a reward metric. Because RL closely mimics how human traders interact with the world, there are various areas of applicability in FSI. In JAX-LOB: A GPU-Accelerated limit order book simulator to unlock large scale reinforcement learning for trading, the authors use GPUs for end-to-end RL training. RL agent training with a GPU has a 7-times speedup relative to a CPU based simulation implementation. The authors then apply this to the problem of optimal trade execution. A second FSI application of RL to optimal trade execution has been reported by JPMorgan in an algorithm called LOXM.
Latency-sensitive, real-time workloads
Being able to transmit, process, and act on data more quickly than others gives an informational advantage. In the financial markets, this is directly equivalent to being able to profit from trading. These real-time, latency-sensitive workloads exist on a spectrum, from the most sensitive to the least sensitive. The specific numbers in the following table are open to debate, but present the general idea.
Band
Latency
Application Examples
1
Less than 1 microsecond
Low-latency trading strategy. Tick 2 trade.
2
1–4 microseconds
Feed handler. Raw or normalized format.
3
40 microseconds
Normalized format and symbology.
4
4–200 milliseconds
Consolidated feed. Full tick.
5
1 second to daily
Intraday and EOD. Reference, Corp, FI, derivatives.
The most latency-sensitive use cases are typically handled by FPGA or custom ASICs. These react to incoming network traffic, like market data, and put triggering logic directly into the network interface controller. Easily reprogrammable PBAs play little to no role in any latency sensitive work, due to the SIMD architecture being designed for the use case of parallel processing large amounts of data with a bandwidth bottleneck of getting data onto the chip.
However, three factors maybe driving change in the role hardware acceleration plays in the low-latency space. Firstly, as PBAs mature, some of their previous barriers are being reduced. For example, NVIDIA’s new NVLink design now enables significantly higher bandwidth relative to previous chip interconnects, meaning that data can get onto the chip far more quickly than before. Comparing the latest NVIDIA GB200 chip against the previous generation NVIDIA H100 chip, NVLink performance has increased 400%, from 900 GBps to 3.6 TBps.
Secondly, some observers believe the race for speed is shifting to a “race for intelligence.” With approximately only ten major firms competing in the top-tier low latency space, the barrier to entry seems almost unsurmountable for other parties. At some point, low-latency hardware and techniques might slowly diffuse through technology supplier offerings, eventually leveling the playing field, perhaps having been driven by new regulations.
Thirdly, although FPGA/ASIC undoubtedly provides the fastest performance, they come at a cost of being a drain on resources. Their developers are hard to hire for, the work has long deployment cycles, and it results in a significant maintenance burden with bugs that are difficult to diagnose and triage. Firms are keen to identify alternatives.
Although the most latency-sensitive work will remain on FPGA/ASIC, there may be a shift of less latency-sensitive work from FPGA/ASIC to GPUs and other PBAs as users weigh the trade-off between speed and other factors. In comparison, easily reprogrammable PBA processors are now simple to hire for, are straightforward to code against and maintain, and allow for relatively rapid innovation. Looking to the future, we may see innovation at the language level, for example, through functional programming with array-languages such as the Co-dfns project, as well as further innovation at the hardware level, with future chips tightly integrating the best components of today’s FPGAs, GPUs and CPUs.
Key Takeaways
In this section, we present three key takeaways. Firstly, the global supply-demand ratio for GPUs is low, meaning price can be high, but availability can be low. This can be a constraining factor for end-user businesses wanting to innovate in this space. AWS helps address this on behalf of its customers in three ways:
Through economies of scale, AWS is able to offer significant availability of the PBAs, including GPUs.
Through in-house research and development, AWS is able to offer its own PBAs, developed and manufactured in-house, which are not subject to the constraints of the wider market, while also having optimized price-performance.
AWS innovates at the software level to improve allocation to the end-user. Therefore, although total capacity might be fixed, by using intelligent allocation algorithms, AWS is better able to meet customers’ needs. For example, Amazon EC2 Capacity Blocks for ML enables guaranteed access to the required PBAs at the point in time they are needed.
The second takeaway is that proprietary software can lock users in to a single supplier and end up acting as a barrier to innovation. In the case of PBAs, the chips that use proprietary software mean that users can’t easily move between chip manufacturers, as opposed to open source software supporting multiple chip manufacturers. Any future supply constraints, such as regional armed conflict, could further exasperate existing supply-demand imbalances. Although migrating existing legacy workloads from an acceleration chip with proprietary software can be challenging, new greenfield workloads can be built on open source libraries without difficulty. In the FSI space, examples of legacy workloads might include risk calculations, and examples of greenfield workloads might include time series prediction using FMs. In the long term, business leaders need to consider and formulate their strategy for moving away from software lock-in, and enable access to wider acceleration hardware offerings, with the cost benefits that can bring.
The final takeaway is that financial services, and the subsection of capital markets in particular, is subject to constant and evolving competitive pressures. Over time, the industry has seen the race for differentiation move from data access rights, to latency, and now to an increased focus on predictive power. Looking to the future, if the world of financial prediction is based in part on a small number of expensive and complex FMs built and trained by a few large global corporates, where will the differentiation come from? Speculative areas could range from at-scale feature engineering to being able to better handle increased regulatory burdens. Whichever field it comes from, it is certain to include data processing and analytics at its core, and therefore benefit from hardware acceleration.
Conclusion
This post aimed to provide business leaders with a non-technical overview of PBAs and their role within the FSI. With this technology currently being regularly discussed in the mainstream media, it is essential business leaders understand the basis of this technology and its potential future role. Nearly every organization is now looking to a data-centric future, enabled by cloud-based infrastructure and real-time analytics, to support revenue-generating AI and ML use cases. One of the ways organizations will be differentiated in this race will be by making the right strategic decisions about technologies, partners, and approaches. This includes topics such as open source versus closed source, build versus buy, tool complexity and associated ease of use, hiring and retention challenges, and price-performance. Such topics are not just technology decisions within a business, but also cultural and strategic ones.
Business leaders are encouraged to reach out to their AWS point of contact and ask how AWS can help their business win in the long term using PBAs. This might result in a range of outcomes, from a short proof of concept against an existing well-defined business problem, to a written strategy document that can be consumed and debated by peers, to onsite technical workshops and business briefing days. Whatever the outcome, the future of this space is sure to be exciting!
Acknowledgements
I would like to thank the following parties for their kind input and guidance in writing this post: Andrea Rodolico, Alex Kimber, and Shruti Koparkar. Any errors are mine alone.
About the Author
Dr. Hugh Christensen works at Amazon Web Services with a specialization in data analytics. He holds undergraduate and master’s degrees from Oxford University, the latter in computational biophysics, and a PhD in Bayesian inference from Cambridge University. Hugh’s areas of interest include time series data, data strategy, data leadership, and using analytics to drive revenue generation. You can connect with Hugh on LinkedIn.