- info@i-genie.co.uk
- 0207 148 4785
Recent advances in language models showcase impressive zero-shot voice conversion (VC) capabilities. Nevertheless, prevailing VC models rooted in language models usually utilize offline conversion from source semantics to acoustic features, necessitating the entirety of the source speech and limiting their application to real-time scenarios.
In this research, a team of researchers from Northwestern Polytechnical University, China, and ByteDance introduce StreamVoice. StreamVoice is a novel streaming language model (LM)-based method for zero-shot voice conversion (VC), allowing real-time conversion with any speaker prompts and source speech. StreamVoice achieves streaming capability by employing a fully causal context-aware LM with a temporal-independent acoustic predictor.
This model alternately processes semantic and acoustic features at each autoregression time step, eliminating the need for complete source speech. To mitigate potential performance degradation in streaming processing due to incomplete context, two strategies are employed:
1) teacher-guided context foresight, where a teacher model summarises present and future semantic context during training to guide the model’s forecasting for missing context.
2) semantic masking strategy, promoting acoustic prediction from preceding corrupted semantic and acoustic input to enhance context-learning ability. Notably, StreamVoice stands out as the first LM-based streaming zero-shot VC model without any future look-ahead. Experimental results showcase StreamVoice’s streaming conversion capability while maintaining zero-shot performance comparable to non-streaming VC systems.
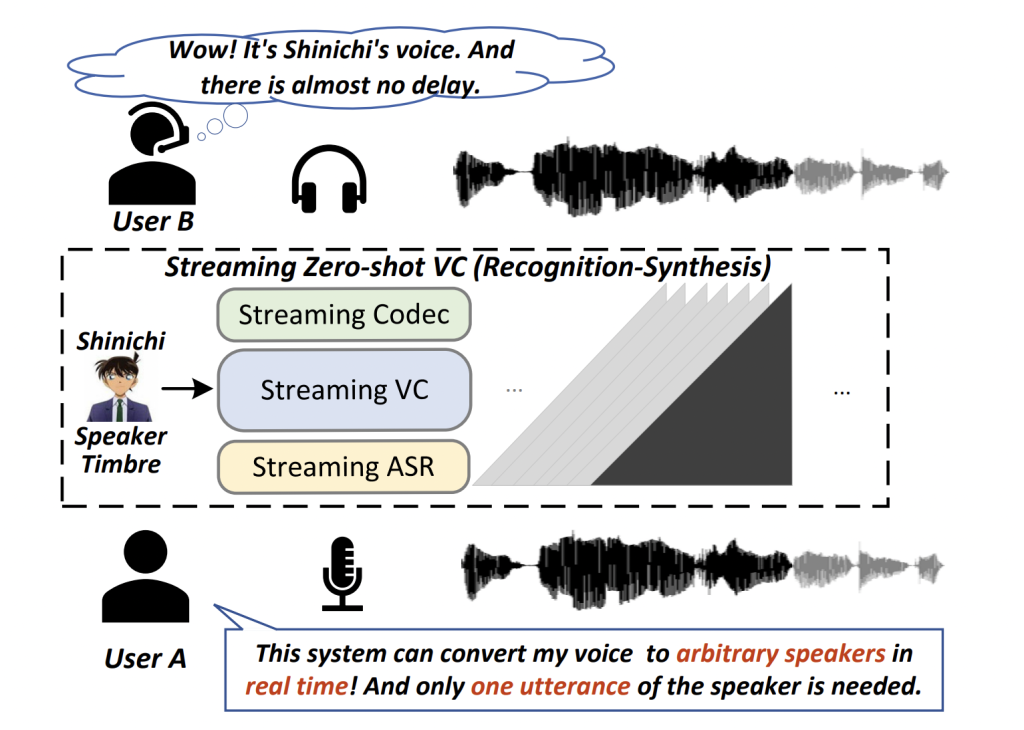
The above figure demonstrates the concept of the streaming zero-shot VC employing the widely used recognition-synthesis framework. StreamVoice is built on this popular paradigm. The experiments conducted illustrate that StreamVoice exhibits the capability to conduct speech conversion in a streaming fashion, achieving high speaker similarity for both familiar and unfamiliar speakers. It maintains performance levels comparable to non-streaming voice conversion (VC) systems. As the initial language model (LM)-based zero-shot VC model without any future lookahead, StreamVoice’s entire pipeline incurs only 124 ms latency for the conversion process. This is notably 2.4 times faster than real-time on a single A100 GPU, even without engineering optimizations. The team’s future work involves using more training data to improve StreamVoice’s modeling ability. They also plan to optimize the streaming pipeline, incorporating a high-fidelity codec with a low bitrate and a unified streaming model.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our 36k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our Telegram Channel
The post This AI Paper from China Introduces StreamVoice: A Novel Language Model-Based Zero-Shot Voice Conversion System Designed for Streaming Scenarios appeared first on MarkTechPost.