- info@i-genie.co.uk
- 0207 148 4785
In the evolving landscape of artificial intelligence and machine learning, the integration of visual perception with language processing has become a frontier of innovation. This integration is epitomized in the development of Multimodal Large Language Models (MLLMs), which have shown remarkable prowess in a range of vision-language tasks. However, these models often falter in basic object perception tasks, such as accurately identifying and counting objects within a visual scene. This discrepancy points to a critical need for improvement in the perceptual capabilities of MLLMs, particularly in accurately recognizing both salient and background entities.
The main challenge this research confronts is enhancing the MLLMs’ ability to perceive objects in a visual scene accurately. Current MLLMs, while adept at complex reasoning tasks, often overlook finer details and background elements, leading to inaccuracies in object perception. This issue is further compounded when models are required to count objects or identify less prominent entities in an image. The goal is to refine these models to achieve a more holistic and accurate understanding of visual scenes without compromising their reasoning abilities.
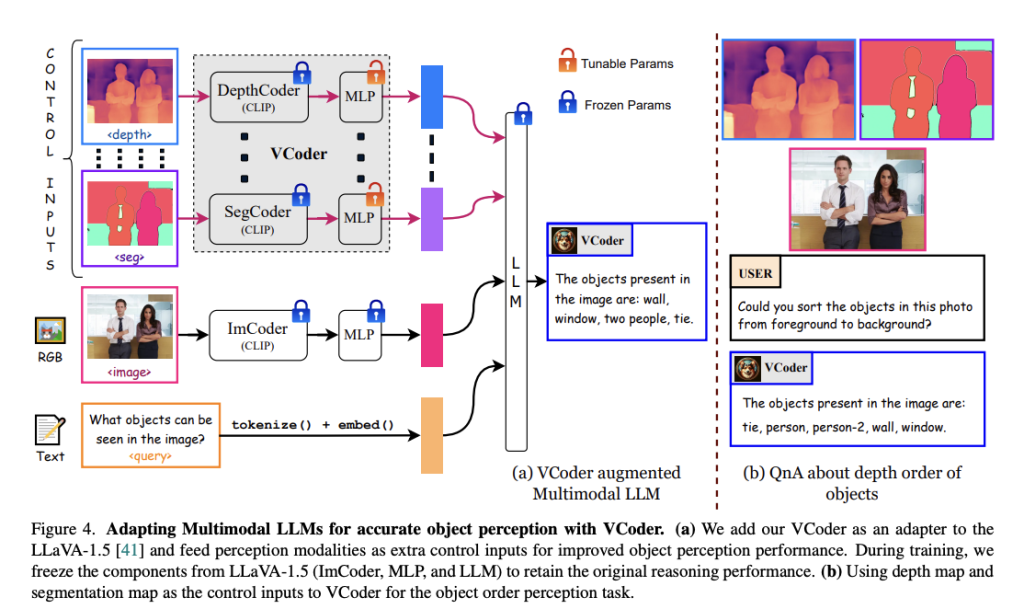
The Versatile vision enCoders (VCoder) method introduced by researchers from Georgia Tech, Microsoft Research, and Picsart AI Research represents an innovative solution to this challenge. VCoder improves MLLMs by incorporating additional perception modalities, such as segmentation or depth maps, into the models. This approach aims to enhance the model’s understanding of the visual world, thereby improving their perception and reasoning capabilities. VCoder operates by using additional vision encoders that project information from perception modalities into the LLM’s space. This involves identifying and reducing higher-order components in weight matrices, focusing on specific layers within the Transformer model. The method is designed to sharpen the models’ object-level perception skills, including counting, without the need for additional training or parameters.
VCoder’s performance was rigorously evaluated against various benchmarks to assess its effectiveness in enhancing object perception tasks. It demonstrated notable improvements in accuracy, particularly in scenarios involving less frequently represented information in training data. This advancement in the models’ robustness and factuality is a significant step forward in the development of MLLMs that are equally adept at perception and reasoning.
The study illustrates that while MLLMs have made significant strides in complex visual reasoning tasks, they often display subpar performance in simpler tasks like counting objects. VCoder, by feeding extra perception modalities as control inputs through additional vision encoders, provides a novel solution to this problem. The researchers used images from the COCO dataset and outputs from off-the-shelf vision perception models to create a COCO Segmentation Text dataset for training and evaluating MLLMs on object perception tasks. They introduced metrics like count score, hallucination score, and depth score to assess object perception abilities in MLLMs.
Extensive experimental evidence proved VCoder’s improved object-level perception skills over existing Multimodal LLMs, including GPT-4V. VCoder was effective in enhancing model performance on less frequently represented information in the training data, indicating an increase in the model’s robustness and factuality. The method allowed MLLMs to handle nuanced and less common data better, thus broadening their applicability and effectiveness.
In conclusion, the VCoder technique marks a significant advance in the optimization of MLLMs. Adopting a selective approach to reducing components in weight matrices successfully enhances these models’ efficiency without imposing additional computational burdens. This approach not only elevates the performance of MLLMs in familiar tasks but also expands their capabilities in processing and understanding complex visual scenes. The research opens new avenues for developing more refined and efficient language models that are proficient in both perception and reasoning.
Check out the Paper and Github. All credit for this research goes to the researchers of this project. Also, don’t forget to join our 35k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
The post Researchers from Microsoft and Georgia Tech Introduce VCoder: Versatile Vision Encoders for Multimodal Large Language Models appeared first on MarkTechPost.