- info@i-genie.co.uk
- 0207 148 4785
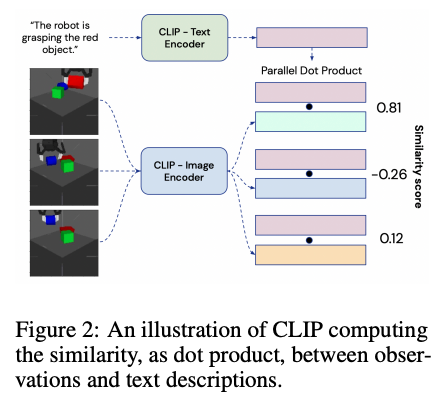
In recent years, there have been significant breakthroughs in the field of Deep Learning, particularly in the popular sub-fields of Artificial Intelligence, including Natural Language Processing (NLP), Natural Language Understanding (NLU) and Computer Vision (CV). Large Language Models (LLMs) have been created in the framework of NLP and demonstrate outstanding language processing and text production skills that are on par with human talents. On the other hand, without any explicit guidance, CV’s Vision Transformers (ViTs) have been able to learn meaningful representations from photos and videos. Vision-linguistic Models (VLMs) have also been developed, which can connect visual inputs with linguistic descriptions or the other way around.
Foundation Models behind a wide range of downstream applications involving various input modalities have been pre-trained on vast amounts of textual and visual data, leading to the emergence of significant attributes like common sense reasoning, proposing and sequencing sub-goals, and visual understanding. The prospect of utilizing Foundation Models’ capabilities to create more effective and all-encompassing reinforcement learning (RL) agents is the topic of research for researchers. RL agents often pick up knowledge through interacting with their surroundings and getting rewards as feedback, but this method of learning by trial and error can be time-consuming and unworkable.
To address the limitations, a team of researchers has proposed a framework that places language at the core of reinforcement learning robotic agents, particularly in scenarios where learning from scratch is required. The core contribution of their work is to demonstrate that by utilizing LLMs and VLMs, they can effectively address several fundamental problems in particularly four RL settings.
Efficient Exploration in Sparse-Reward Settings: It is difficult for RL agents to learn the best behavior because they frequently find it difficult to explore settings with few rewards. The suggested approach makes exploration and learning in these contexts more effective by utilizing the knowledge kept in Foundation Models.
Reusing gathered Data for Sequential Learning: The framework allows RL agents to build on previously gathered data rather than beginning from scratch each time a new task is met, aiding the sequential learning of new tasks.
Scheduling learned abilities for NewTasks: The framework supports the scheduling of learned abilities, enabling agents to handle novel tasks with their current knowledge efficiently.
Learning from Observations of Expert Agents: By using Foundation Models to learn from observations of expert agents, learning processes can become more efficient and quick.
The team has summarized the main contributions as follows –
The framework has been made in a way that enables the RL agent to reason and make judgments more effectively based on textual information by using language models and vision language models as the fundamental reasoning tools. The agent’s capacity to comprehend challenging tasks and settings is improved by this method.
The proposed framework shows its efficiency in resolving fundamental RL problems that in the past needed distinct, specially created algorithms.
The new framework outperforms conventional baseline techniques in the sparse-reward robotic manipulation setting.
The framework also shows that it can efficiently use previously taught skills to complete tasks. The RL agent’s generalization and adaptability are enhanced by the ability to transfer learned information to new situations.
It demonstrates how the RL agent may accurately learn from observable demonstrations by imitating films of human experts.
[ Trending ] Meet Pixis AI: An Emerging Startup Providing Codeless AI Solutions
In conclusion, the study shows that language models and vision language models have the ability to serve as the core components of reinforcement learning agents’ reasoning.
Check out the Paper. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 26k+ ML SubReddit, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
The post Researchers from Imperial College London and DeepMind Designed an AI Framework that Uses Language as the Core Reasoning Tool of an RL Agent appeared first on MarkTechPost.