- info@i-genie.co.uk
- 0207 148 4785
Maintaining machine learning (ML) workflows in production is a challenging task because it requires creating continuous integration and continuous delivery (CI/CD) pipelines for ML code and models, model versioning, monitoring for data and concept drift, model retraining, and a manual approval process to ensure new versions of the model satisfy both performance and compliance requirements.
In this post, we describe how to create an MLOps workflow for batch inference that automates job scheduling, model monitoring, retraining, and registration, as well as error handling and notification by using Amazon SageMaker, Amazon EventBridge, AWS Lambda, Amazon Simple Notification Service (Amazon SNS), HashiCorp Terraform, and GitLab CI/CD. The presented MLOps workflow provides a reusable template for managing the ML lifecycle through automation, monitoring, auditability, and scalability, thereby reducing the complexities and costs of maintaining batch inference workloads in production.
Solution overview
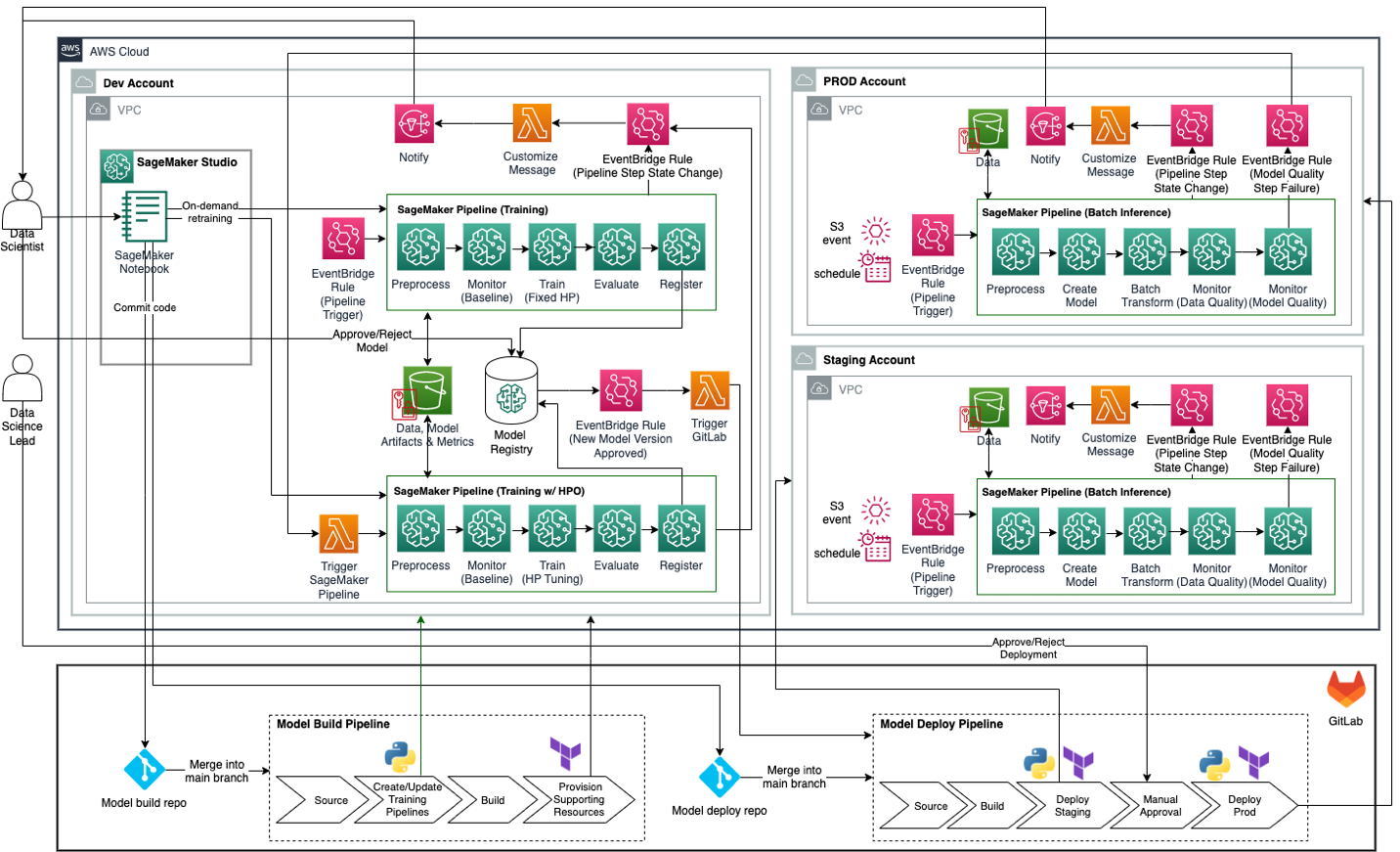
The following figure illustrates the proposed target MLOps architecture for enterprise batch inference for organizations who use GitLab CI/CD and Terraform infrastructure as code (IaC) in conjunction with AWS tools and services. GitLab CI/CD serves as the macro-orchestrator, orchestrating model build and model deploy pipelines, which include sourcing, building, and provisioning Amazon SageMaker Pipelines and supporting resources using the SageMaker Python SDK and Terraform. SageMaker Python SDK is used to create or update SageMaker pipelines for training, training with hyperparameter optimization (HPO), and batch inference. Terraform is used to create additional resources such as EventBridge rules, Lambda functions, and SNS topics for monitoring SageMaker pipelines and sending notifications (for example, when a pipeline step fails or succeeds). SageMaker Pipelines serves as the orchestrator for ML model training and inference workflows.
This architecture design represents a multi-account strategy where ML models are built, trained, and registered in a central model registry within a data science development account (which has more controls than a typical application development account). Then, inference pipelines are deployed to staging and production accounts using automation from DevOps tools such as GitLab CI/CD. The central model registry could optionally be placed in a shared services account as well. Refer to Operating model for best practices regarding a multi-account strategy for ML.
In the following subsections, we discuss different aspects of the architecture design in detail.
Infrastructure as code
IaC offers a way to manage IT infrastructure through machine-readable files, ensuring efficient version control. In this post and the accompanying code sample, we demonstrate how to use HashiCorp Terraform with GitLab CI/CD to manage AWS resources effectively. This approach underscores the key benefit of IaC, offering a transparent and repeatable process in IT infrastructure management.
Model training and retraining
In this design, the SageMaker training pipeline runs on a schedule (via EventBridge) or based on an Amazon Simple Storage Service (Amazon S3) event trigger (for example, when a trigger file or new training data, in case of a single training data object, is placed in Amazon S3) to regularly recalibrate the model with new data. This pipeline does not introduce structural or material changes to the model because it uses fixed hyperparameters that have been approved during the enterprise model review process.
The training pipeline registers the newly trained model version in the Amazon SageMaker Model Registry if the model exceeds a predefined model performance threshold (for example, RMSE for regression and F1 score for classification). When a new version of the model is registered in the model registry, it triggers a notification to the responsible data scientist via Amazon SNS. The data scientist then needs to review and manually approve the latest version of the model in the Amazon SageMaker Studio UI or via an API call using the AWS Command Line Interface (AWS CLI) or AWS SDK for Python (Boto3) before the new version of model can be utilized for inference.
The SageMaker training pipeline and its supporting resources are created by the GitLab model build pipeline, either via a manual run of the GitLab pipeline or automatically when code is merged into the main branch of the model build Git repository.
Batch inference
The SageMaker batch inference pipeline runs on a schedule (via EventBridge) or based on an S3 event trigger as well. The batch inference pipeline automatically pulls the latest approved version of the model from the model registry and uses it for inference. The batch inference pipeline includes steps for checking data quality against a baseline created by the training pipeline, as well as model quality (model performance) if ground truth labels are available.
If the batch inference pipeline discovers data quality issues, it will notify the responsible data scientist via Amazon SNS. If it discovers model quality issues (for example, RMSE is greater than a pre-specified threshold), the pipeline step for the model quality check will fail, which will in turn trigger an EventBridge event to start the training with HPO pipeline.
The SageMaker batch inference pipeline and its supporting resources are created by the GitLab model deploy pipeline, either via a manual run of the GitLab pipeline or automatically when code is merged into the main branch of the model deploy Git repository.
Model tuning and retuning
The SageMaker training with HPO pipeline is triggered when the model quality check step of the batch inference pipeline fails. The model quality check is performed by comparing model predictions with the actual ground truth labels. If the model quality metric (for example, RMSE for regression and F1 score for classification) doesn’t meet a pre-specified criterion, the model quality check step is marked as failed. The SageMaker training with HPO pipeline can also be triggered manually (in the SageMaker Studio UI or via an API call using the AWS CLI or SageMaker Python SDK) by the responsible data scientist if needed. Because the model hyperparameters are changing, the responsible data scientist needs to obtain approval from the enterprise model review board before the new model version can be approved in the model registry.
The SageMaker training with HPO pipeline and its supporting resources are created by the GitLab model build pipeline, either via a manual run of the GitLab pipeline or automatically when code is merged into the main branch of the model build Git repository.
Model monitoring
Data statistics and constraints baselines are generated as part of the training and training with HPO pipelines. They are saved to Amazon S3 and also registered with the trained model in the model registry if the model passes evaluation. The proposed architecture for the batch inference pipeline uses Amazon SageMaker Model Monitor for data quality checks, while using custom Amazon SageMaker Processing steps for model quality check. This design decouples data and model quality checks, which in turn allows you to only send a warning notification when data drift is detected; and trigger the training with HPO pipeline when a model quality violation is detected.
Model approval
After a newly trained model is registered in the model registry, the responsible data scientist receives a notification. If the model has been trained by the training pipeline (recalibration with new training data while hyperparameters are fixed), there is no need for approval from the enterprise model review board. The data scientist can review and approve the new version of the model independently. On the other hand, if the model has been trained by the training with HPO pipeline (retuning by changing hyperparameters), the new model version needs to go through the enterprise review process before it can be used for inference in production. When the review process is complete, the data scientist can proceed and approve the new version of the model in the model registry. Changing the status of the model package to Approved will trigger a Lambda function via EventBridge, which will in turn trigger the GitLab model deploy pipeline via an API call. This will automatically update the SageMaker batch inference pipeline to utilize the latest approved version of the model for inference.
There are two main ways to approve or reject a new model version in the model registry: using the AWS SDK for Python (Boto3) or from the SageMaker Studio UI. By default, both the training pipeline and training with HPO pipeline set ModelApprovalStatus to PendingManualApproval. The responsible data scientist can update the approval status for the model by calling the update_model_package API from Boto3. Refer to Update the Approval Status of a Model for details about updating the approval status of a model via the SageMaker Studio UI.
Data I/O design
SageMaker interacts directly with Amazon S3 for reading inputs and storing outputs of individual steps in the training and inference pipelines. The following diagram illustrates how different Python scripts, raw and processed training data, raw and processed inference data, inference results and ground truth labels (if available for model quality monitoring), model artifacts, training and inference evaluation metrics (model quality monitoring), as well as data quality baselines and violation reports (for data quality monitoring) can be organized within an S3 bucket. The direction of arrows in the diagram indicates which files are inputs or outputs from their respective steps in the SageMaker pipelines. Arrows have been color-coded based on pipeline step type to make them easier to read. The pipeline will automatically upload Python scripts from the GitLab repository and store output files or model artifacts from each step in the appropriate S3 path.
The data engineer is responsible for the following:
Uploading labeled training data to the appropriate path in Amazon S3. This includes adding new training data regularly to ensure the training pipeline and training with HPO pipeline have access to recent training data for model retraining and retuning, respectively.
Uploading input data for inference to the appropriate path in S3 bucket before a planned run of the inference pipeline.
Uploading ground truth labels to the appropriate S3 path for model quality monitoring.
The data scientist is responsible for the following:
Preparing ground truth labels and providing them to the data engineering team for uploading to Amazon S3.
Taking the model versions trained by the training with HPO pipeline through the enterprise review process and obtaining necessary approvals.
Manually approving or rejecting newly trained model versions in the model registry.
Approving the production gate for the inference pipeline and supporting resources to be promoted to production.
Sample code
In this section, we present a sample code for batch inference operations with a single-account setup as shown in the following architecture diagram. The sample code can be found in the GitHub repository, and can serve as a starting point for batch inference with model monitoring and automatic retraining using quality gates often required for enterprises. The sample code differs from the target architecture in the following ways:
It uses a single AWS account for building and deploying the ML model and supporting resources. Refer to Organizing Your AWS Environment Using Multiple Accounts for guidance on multi-account setup on AWS.
It uses a single GitLab CI/CD pipeline for building and deploying the ML model and supporting resources.
When a new version of the model is trained and approved, the GitLab CI/CD pipeline is not triggered automatically and needs to be run manually by the responsible data scientist to update the SageMaker batch inference pipeline with the latest approved version of the model.
It only supports S3 event-based triggers for running the SageMaker training and inference pipelines.
Prerequisites
You should have the following prerequisites before deploying this solution:
An AWS account
SageMaker Studio
A SageMaker execution role with Amazon S3 read/write and AWS Key Management Service (AWS KMS) encrypt/decrypt permissions
An S3 bucket for storing data, scripts, and model artifacts
Terraform version 0.13.5 or greater
GitLab with a working Docker runner for running the pipelines
The AWS CLI
jq
unzip
Python3 (Python 3.7 or greater) and the following Python packages:
boto3
sagemaker
pandas
pyyaml
Repository structure
The GitHub repository contains the following directories and files:
/code/lambda_function/ – This directory contains the Python file for a Lambda function that prepares and sends notification messages (via Amazon SNS) about the SageMaker pipelines’ step state changes
/data/ – This directory includes the raw data files (training, inference, and ground truth data)
/env_files/ – This directory contains the Terraform input variables file
/pipeline_scripts/ – This directory contains three Python scripts for creating and updating training, inference, and training with HPO SageMaker pipelines, as well as configuration files for specifying each pipeline’s parameters
/scripts/ – This directory contains additional Python scripts (such as preprocessing and evaluation) that are referenced by the training, inference, and training with HPO pipelines
.gitlab-ci.yml – This file specifies the GitLab CI/CD pipeline configuration
/events.tf – This file defines EventBridge resources
/lambda.tf – This file defines the Lambda notification function and the associated AWS Identity and Access Management (IAM) resources
/main.tf – This file defines Terraform data sources and local variables
/sns.tf – This file defines Amazon SNS resources
/tags.json – This JSON file allows you to declare custom tag key-value pairs and append them to your Terraform resources using a local variable
/variables.tf – This file declares all the Terraform variables
Variables and configuration
The following table shows the variables that are used to parameterize this solution. Refer to the ./env_files/dev_env.tfvars file for more details.
Name
Description
bucket_name
S3 bucket that is used to store data, scripts, and model artifacts
bucket_prefix
S3 prefix for the ML project
bucket_train_prefix
S3 prefix for training data
bucket_inf_prefix
S3 prefix for inference data
notification_function_name
Name of the Lambda function that prepares and sends notification messages about SageMaker pipelines’ step state changes
custom_notification_config
The configuration for customizing notification message for specific SageMaker pipeline steps when a specific pipeline run status is detected
email_recipient
The email address list for receiving SageMaker pipelines’ step state change notifications
pipeline_inf
Name of the SageMaker inference pipeline
pipeline_train
Name of the SageMaker training pipeline
pipeline_trainwhpo
Name of SageMaker training with HPO pipeline
recreate_pipelines
If set to true, the three existing SageMaker pipelines (training, inference, training with HPO) will be deleted and new ones will be created when GitLab CI/CD is run
model_package_group_name
Name of the model package group
accuracy_mse_threshold
Maximum value of MSE before requiring an update to the model
role_arn
IAM role ARN of the SageMaker pipeline execution role
kms_key
KMS key ARN for Amazon S3 and SageMaker encryption
subnet_id
Subnet ID for SageMaker networking configuration
sg_id
Security group ID for SageMaker networking configuration
upload_training_data
If set to true, training data will be uploaded to Amazon S3, and this upload operation will trigger the run of the training pipeline
upload_inference_data
If set to true, inference data will be uploaded to Amazon S3, and this upload operation will trigger the run of the inference pipeline
user_id
The employee ID of the SageMaker user that is added as a tag to SageMaker resources
Deploy the solution
Complete the following steps to deploy the solution in your AWS account:
Clone the GitHub repository into your working directory.
Review and modify the GitLab CI/CD pipeline configuration to suit your environment. The configuration is specified in the ./gitlab-ci.yml file.
Refer to the README file to update the general solution variables in the ./env_files/dev_env.tfvars file. This file contains variables for both Python scripts and Terraform automation.
Check the additional SageMaker Pipelines parameters that are defined in the YAML files under ./batch_scoring_pipeline/pipeline_scripts/. Review and update the parameters if necessary.
Review the SageMaker pipeline creation scripts in ./pipeline_scripts/ as well as the scripts that are referenced by them in the ./scripts/ folder. The example scripts provided in the GitHub repo are based on the Abalone dataset. If you are going to use a different dataset, ensure you update the scripts to suit your particular problem.
Put your data files into the ./data/ folder using the following naming convention. If you are using the Abalone dataset along with the provided example scripts, ensure the data files are headerless, the training data includes both independent and target variables with the original order of columns preserved, the inference data only includes independent variables, and the ground truth file only includes the target variable.
training-data.csv
inference-data.csv
ground-truth.csv
Commit and push the code to the repository to trigger the GitLab CI/CD pipeline run (first run). Note that the first pipeline run will fail on the pipeline stage because there’s no approved model version yet for the inference pipeline script to use. Review the step log and verify a new SageMaker pipeline named TrainingPipeline has been successfully created.
Open the SageMaker Studio UI, then review and run the training pipeline.
After the successful run of the training pipeline, approve the registered model version in the model registry, then rerun the entire GitLab CI/CD pipeline.
Review the Terraform plan output in the build stage. Approve the manual apply stage in the GitLab CI/CD pipeline to resume the pipeline run and authorize Terraform to create the monitoring and notification resources in your AWS account.
Finally, review the SageMaker pipelines’ run status and output in the SageMaker Studio UI and check your email for notification messages, as shown in the following screenshot. The default message body is in JSON format.
SageMaker pipelines
In this section, we describe the three SageMaker pipelines within the MLOps workflow.
Training pipeline
The training pipeline is composed of the following steps:
Preprocessing step, including feature transformation and encoding
Data quality check step for generating data statistics and constraints baseline using the training data
Training step
Training evaluation step
Condition step to check whether the trained model meets a pre-specified performance threshold
Model registration step to register the newly trained model in the model registry if the trained model meets the required performance threshold
Both the skip_check_data_quality and register_new_baseline_data_quality parameters are set to True in the training pipeline. These parameters instruct the pipeline to skip the data quality check and just create and register new data statistics or constraints baselines using the training data. The following figure depicts a successful run of the training pipeline.
Batch inference pipeline
The batch inference pipeline is composed of the following steps:
Creating a model from the latest approved model version in the model registry
Preprocessing step, including feature transformation and encoding
Batch inference step
Data quality check preprocessing step, which creates a new CSV file containing both input data and model predictions to be used for the data quality check
Data quality check step, which checks the input data against baseline statistics and constraints associated with the registered model
Condition step to check whether ground truth data is available. If ground truth data is available, the model quality check step will be performed
Model quality calculation step, which calculates model performance based on ground truth labels
Both the skip_check_data_quality and register_new_baseline_data_quality parameters are set to False in the inference pipeline. These parameters instruct the pipeline to perform a data quality check using the data statistics or constraints baseline associated with the registered model (supplied_baseline_statistics_data_quality and supplied_baseline_constraints_data_quality) and skip creating or registering new data statistics and constraints baselines during inference. The following figure illustrates a run of the batch inference pipeline where the data quality check step has failed due to poor performance of the model on the inference data. In this particular case, the training with HPO pipeline will be triggered automatically to fine-tune the model.
Training with HPO pipeline
The training with HPO pipeline is composed of the following steps:
Preprocessing step (feature transformation and encoding)
Data quality check step for generating data statistics and constraints baseline using the training data
Hyperparameter tuning step
Training evaluation step
Condition step to check whether the trained model meets a pre-specified accuracy threshold
Model registration step if the best trained model meets the required accuracy threshold
Both the skip_check_data_quality and register_new_baseline_data_quality parameters are set to True in the training with HPO pipeline. The following figure depicts a successful run of the training with HPO pipeline.
Clean up
Complete the following steps to clean up your resources:
Employ the destroy stage in the GitLab CI/CD pipeline to eliminate all resources provisioned by Terraform.
Use the AWS CLI to list and remove any remaining pipelines that are created by the Python scripts.
Optionally, delete other AWS resources such as the S3 bucket or IAM role created outside the CI/CD pipeline.
Conclusion
In this post, we demonstrated how enterprises can create MLOps workflows for their batch inference jobs using Amazon SageMaker, Amazon EventBridge, AWS Lambda, Amazon SNS, HashiCorp Terraform, and GitLab CI/CD. The presented workflow automates data and model monitoring, model retraining, as well as batch job runs, code versioning, and infrastructure provisioning. This can lead to significant reductions in complexities and costs of maintaining batch inference jobs in production. For more information about implementation details, review the GitHub repo.
About the Authors
Hasan Shojaei is a Sr. Data Scientist with AWS Professional Services, where he helps customers across different industries such as sports, insurance, and financial services solve their business challenges through the use of big data, machine learning, and cloud technologies. Prior to this role, Hasan led multiple initiatives to develop novel physics-based and data-driven modeling techniques for top energy companies. Outside of work, Hasan is passionate about books, hiking, photography, and history.
Wenxin Liu is a Sr. Cloud Infrastructure Architect. Wenxin advises enterprise companies on how to accelerate cloud adoption and supports their innovations on the cloud. He’s a pet lover and is passionate about snowboarding and traveling.
Vivek Lakshmanan is a Machine Learning Engineer at Amazon. He has a Master’s degree in Software Engineering with specialization in Data Science and several years of experience as an MLE. Vivek is excited on applying cutting-edge technologies and building AI/ML solutions to customers on cloud. He is passionate about Statistics, NLP and Model Explainability in AI/ML. In his spare time, he enjoys playing cricket and taking road trips.
Andy Cracchiolo is a Cloud Infrastructure Architect. With more than 15 years in IT infrastructure, Andy is an accomplished and results-driven IT professional. In addition to optimizing IT infrastructure, operations, and automation, Andy has a proven track record of analyzing IT operations, identifying inconsistencies, and implementing process enhancements that increase efficiency, reduce costs, and increase profits.