- info@i-genie.co.uk
- 0207 148 4785
Significant advancements in speech technology have been made over the past decade, allowing it to be incorporated into various consumer items. It takes a lot of labeled data, in this case, many thousands of hours of audio with transcriptions, to train a good machine learning model for such jobs. This information only exists in some languages. For instance, out of the 7,000+ languages in use today, only about 100 are supported by current voice recognition algorithms.
Recently, the amount of labeled data needed to construct speech systems have been drastically reduced because of self-supervised speech representations. Despite progress, major current efforts still only cover around 100 languages.
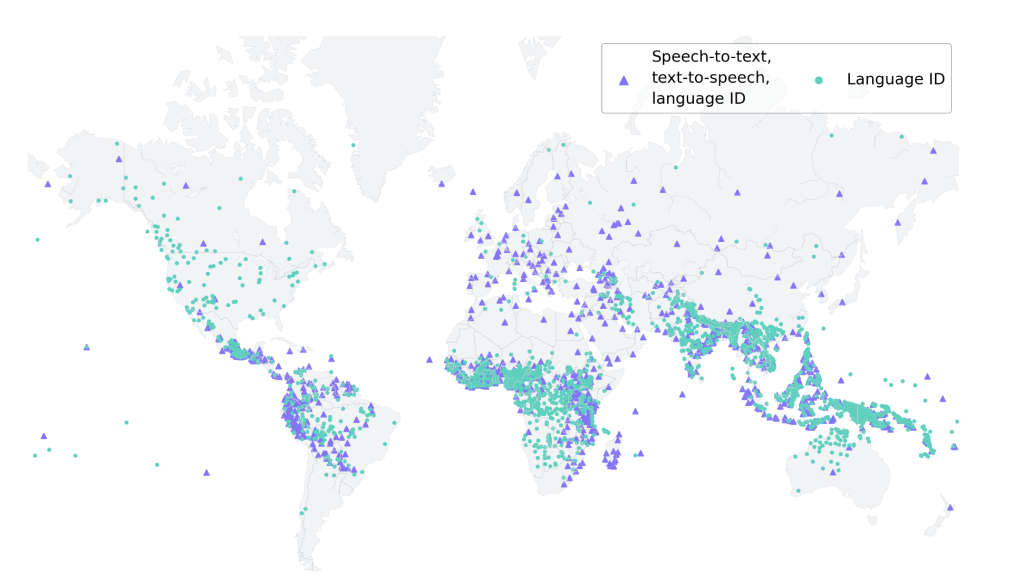
Facebook’s Massively Multilingual Speech (MMS) project combines wav2vec 2.0 with a new dataset that contains labeled data for over 1,100 languages and unlabeled data for almost 4,000 languages to address some of these obstacles. Based on their findings, the Massively Multilingual Speech models are superior to the state-of-the-art methods and support ten times as many languages.
Since the greatest available speech datasets only include up to 100 languages, their initial goal was to collect audio data for hundreds of languages. As a result, they looked to religious writings like the Bible, which have been translated into many languages and whose translations have been extensively examined for text-based language translation research. People have recorded themselves reading these translations and made the audio files available online. This research compiled a collection of New Testament readings in over 1,100 languages, yielding an average of 32 hours of data per language.
Their investigation reveals that the proposed models perform similarly well for male and female voices, even though this data is from a specific domain and is typically read by male speakers. Even though the recordings are religious, the research indicates that this does not unduly bias the model toward producing more religious language. According to the researchers, this is because they employ a Connectionist Temporal Classification strategy, which is more limited than large language models (LLMs) or sequence-to-sequence models for voice recognition.
The team preprocessed tha data by combining a highly efficient forced alignment approach that can handle recordings that are 20 minutes or longer with an alignment model that was trained using data from over 100 different languages. To eliminate possibly skewed information, they used numerous iterations of this procedure plus a cross-validation filtering step based on model accuracy. They integrated the alignment technique into PyTorch and made the alignment model publicly available so that other academics may use it to generate fresh speech datasets.
There is insufficient information to train traditional supervised speech recognition models with only 32 hours of data per language. The team relied on wav2vec 2.0 to train effective systems, drastically decreasing the quantity of previously required labeled data. Specifically, they used over 1,400 unique languages to train self-supervised models on over 500,000 hours of voice data, approximately five times more languages than any previous effort.
The researchers employed pre-existing benchmark datasets like FLEURS to assess the performance of models trained on the Massively Multilingual Speech data. Using a 1B parameter wav2vec 2.0 model, they trained a multilingual speech recognition system on over 1,100 languages. The performance degrades slightly as the number of languages grows: The character mistake rate only goes up by roughly 0.4% from 61 to 1,107 languages, while the language coverage goes up by nearly 18 times.
Comparing the Massively Multilingual Speech data to OpenAI’s Whisper, the researchers discovered that models trained on the former achieve half the word error rate. At the same time, the latter covers 11 times as many languages. This illustrates that the model can compete favorably with the state-of-the-art in voice recognition.
The team also used their datasets and publicly available datasets like FLEURS and CommonVoice to train a language identification (LID) model for more than 4,000 languages. Then it tested it on the FLEURS LID challenge. The findings show that performance is still excellent even when 40 times as many languages are supported. They also developed speech synthesis systems for more than 1,100 languages. The majority of existing text-to-speech algorithms are trained on single-speaker voice datasets.
The team foresees a world where one model can handle many speech tasks across all languages. While they did train individual models for each task—recognition, synthesis, and identification of language—they believe that in the future, a single model will be able to handle all of these functions and more, improving performance in every area.
Check out the Paper, Blog, and Github Link. Don’t forget to join our 22k+ ML SubReddit, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more. If you have any questions regarding the above article or if we missed anything, feel free to email us at Asif@marktechpost.com
Check Out 100’s AI Tools in AI Tools Club
The post Meta AI Launches Massively Multilingual Speech (MMS) Project: Introducing Speech-To-Text, Text-To-Speech, And More For 1,000+ Languages appeared first on MarkTechPost.