- info@i-genie.co.uk
- 0207 148 4785
With new releases and introductions in the field of Artificial Intelligence (AI), Large Language Models (LLMs) are advancing significantly. They are showcasing their incredible capability of generating and comprehending natural language. However, there are certain difficulties experienced by LLMs with an emphasis on English when managing non-English languages, especially those with constrained resources. Although the advent of generative multilingual LLMs is recognized, the language coverage of current models is considered inadequate.
An important milestone was reached when the XLM-R auto-encoding model was introduced with 278M parameters with language coverage from 100 languages to 534 languages. Even the Glot500-c corpora, which spans 534 languages from 47 language families, benefited the low-resource languages. Other effective strategies to address data scarcity include vocabulary extension and ongoing pretraining.
The success of these models’ enormous language adoption serves as inspiration for more developments in this area. In a recent study, a team of researchers has specifically addressed the limitations of previous efforts that concentrated on small model sizes, with the goal of expanding the capabilities of LLMs to cover a wider range of languages. In order to improve contextual and linguistic relevance across a range of languages, the study discusses language adaptation strategies for LLMs with model parameters scaling up to 10 billion.
There are difficulties in adapting LLMs to low-resource languages, including problems with data sparsity, vocabulary peculiar to a given area, and linguistic variation. The team has suggested solutions, such as expanding vocabulary, continuing to train open LLMs, and utilizing adaption strategies like LoRA low-rank reparameterization.
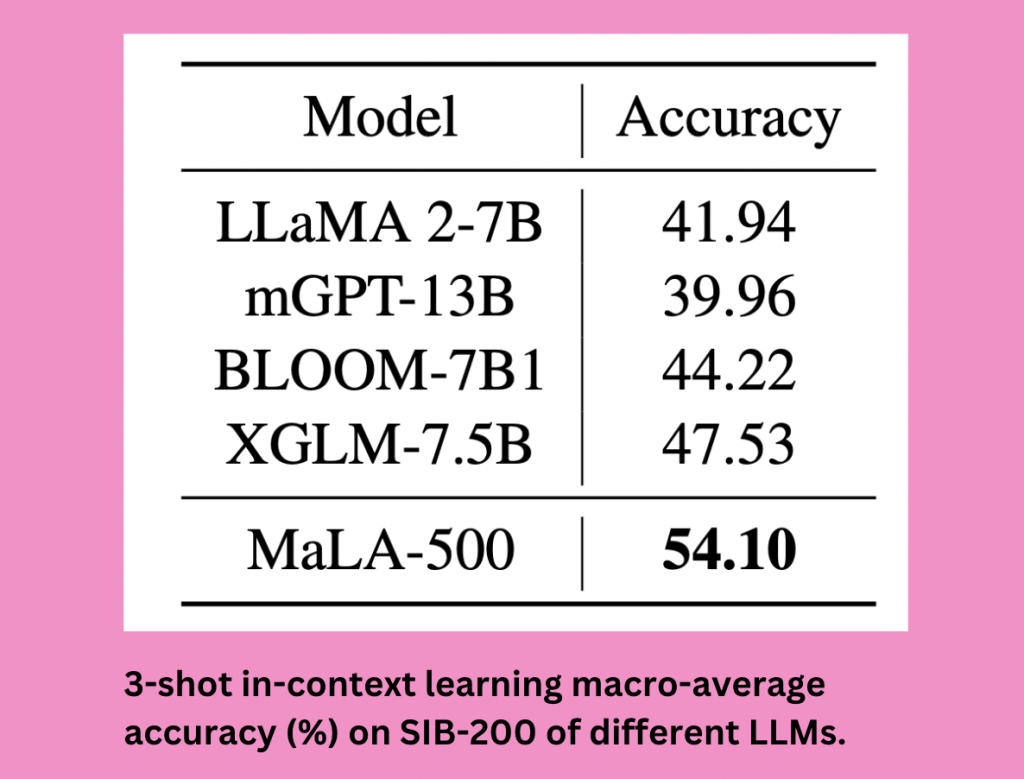
A team of researchers associated with LMU Munich, Munich Center for Machine Learning, University of Helsinki, Instituto Superior Técnico (Lisbon ELLIS Unit), Instituto de Telecomunicações, and Unbabel has come up with a model called MaLA-500. MaLA-500 is a brand-new large language model designed to span a wide spectrum of 534 languages. Vocabulary expansion has been used in MaLA-500 training, along with ongoing LLaMA 2 pretraining using Glot500-c. The team has conducted an analysis using the SIB-200 dataset, which has shown that MaLA-500 performs better than currently available open LLMs with comparable or marginally bigger model sizes. It has achieved some amazing in-context learning outcomes, describing a model’s capacity to comprehend and produce language within a particular environment demonstrating its adaptability and significance in a range of linguistic contexts.
MaLA-500 is a great solution for the current LLMs’ inability to support low-resource languages. It exhibits state-of-the-art in-context learning results through unique approaches such as vocabulary extension and continuous pretraining. Vocabulary extension is the process of expanding the model’s vocabulary to cover a wider range of languages so that it can comprehend and produce material in a variety of languages.
In conclusion, this study is important because it increases the accessibility of language learning modules (LLMs), which makes them useful for a wide range of language-specific use cases, particularly for low-resource languages.
Check out the Paper and Model. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our 36k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our Telegram Channel
The post Meet MaLA-500: A Novel Large Language Model Designed to Cover an Extensive Range of 534 Languages appeared first on MarkTechPost.