- info@i-genie.co.uk
- 0207 148 4785
The recent advancements in Artificial Intelligence have enabled the development of Large Language Models (LLMs) with a significantly large number of parameters, with some of them reaching into billions (for example, LLaMA-2 that comes in sizes of 7B, 13B, and even 70B parameters). With such specifications, the model is able to achieve very high performances across diverse tasks, making it a powerful tool for various AI applications. The downside to this, however, is that the deployment of such models comes with an expensive cost, and devices like phones do not possess enough memory to host them.
Various pruning techniques have emerged in the past to overcome this issue. However, many lead to a significant performance degradation after pruning. Moreover, these methods do not readily extend to structured pruning. Therefore, a team of researchers from Imperial College London, Qualcomm AI Research, QUVA Lab, and the University of Amsterdam have introduced LLM Surgeon, a framework for unstructured, semi-structured, and structured LLM pruning that prunes the model in multiple steps, updating the weights and curvature estimates between each step. According to the experiments conducted by the researchers, their framework allows for the pruning of LLMs by up to 30% without any significant performance degradation, demonstrating its effectiveness.
The framework uses weight magnitude and activations from forward passes and gradient information from backward passes to relate weight removal costs to the true final objective. The researchers have improved the previous works in weight pruning by using more accurate approximations to the loss curvature and more weight correlations to update remaining weights.
The accuracy of pruning depends on accurately estimating the local curvature and simultaneously overcoming the memory cost that is associated with storing the exact curvature.
LLM Surgeon uses the KFAC approximation for this task, a popular method for curvature approximation, because of its memory efficiency. This method allows the framework to compute the dynamic allocation of structures that can be removed. Moreover, it also allows the updation of the remaining weights, accounting for the removal.
The framework prunes multiple weights at once to reach the target model size while inflicting the least possible cost. Additionally, LLM Surgeon prunes in multiple steps to improve the performance-to-sparsity. The researchers justified their approach by showing that the pruning performance increased with more shots.
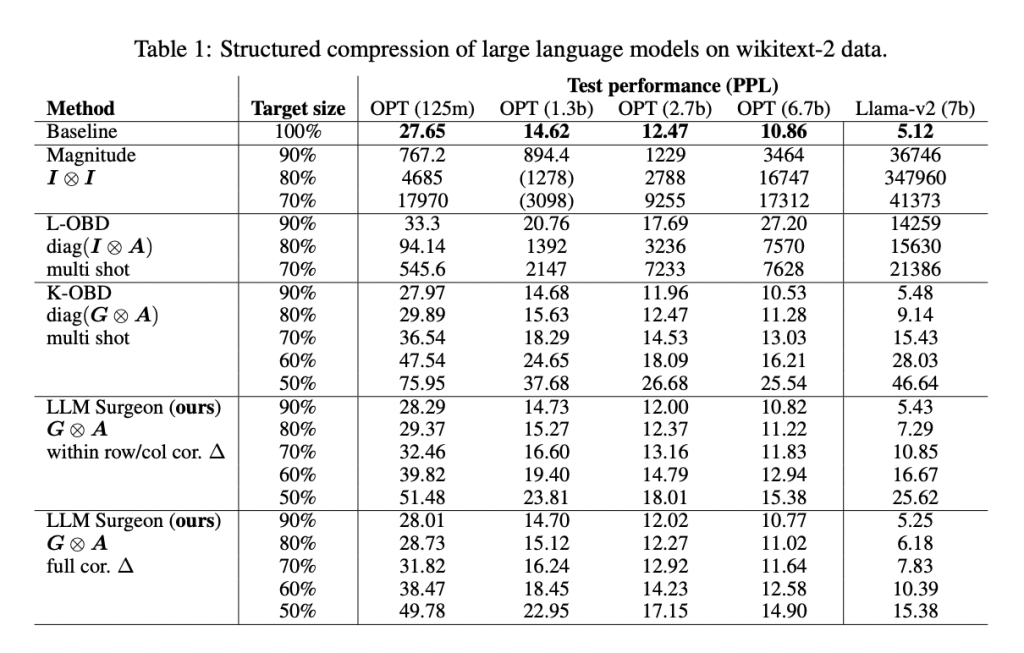
The researchers evaluated the performance of LLM Surgeon on language modeling tasks on models like OPT and LLaMA-2, using data from the wikitext-2 dataset. For structured compression, the framework allows the model size to be reduced by up to 30% without any significant loss. Moreover, it performs better than all baselines, achieving the best performance for each target size. For semi-structured and unstructured compression as well, LLM Surgeon outperforms all baselines, demonstrating the best performance across target sizes.
In conclusion, LLM Surgeon addresses the problem posed by LLMs with a significantly large number of parameters in terms of deployment. The results show that it can prune rows and columns from a range of LLMs by 20-30% without significant loss in performance. It also achieves state-of-the-art results in unstructured and semi-structured pruning of LLMs, enabling an easier deployment process.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to join our 35k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, LinkedIn Group, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
The post Meet LLM Surgeon: A New Machine Learning Framework for Unstructured, Semi-Structured, and Structured Pruning of Large Language Models (LLMs) appeared first on MarkTechPost.