- info@i-genie.co.uk
- 0207 148 4785
Language models develop general-purpose representations transferable to almost any language interpretation or generating job by being pretrained to anticipate the next token at an astounding scale. Different approaches to aligning language models have thus been put forth to facilitate this transfer, with a particular emphasis on instruction tuning over sizable datasets with millions of examples and, more recently, reinforcement learning from human feedback (RLHF) gathered over millions of interactions with human annotators, for existing alignment techniques to function at ChatGPT levels, large computing, and specialized data resources are needed.
However, they show that with a good language model already trained, very good performance may be obtained by just tweaking 1,000 properly chosen training instances. According to their hypothesis, alignment may be a quick and easy procedure where the model learns the format or style of engaging users to disclose the skills and information already learned during pretraining. They collect 1,000 instances that resemble authentic user cues and excellent replies to verify this idea. They choose 750 of the best questions and responses from online discussion boards like Stack Exchange and wikiHow, evaluating them for quality and variety.
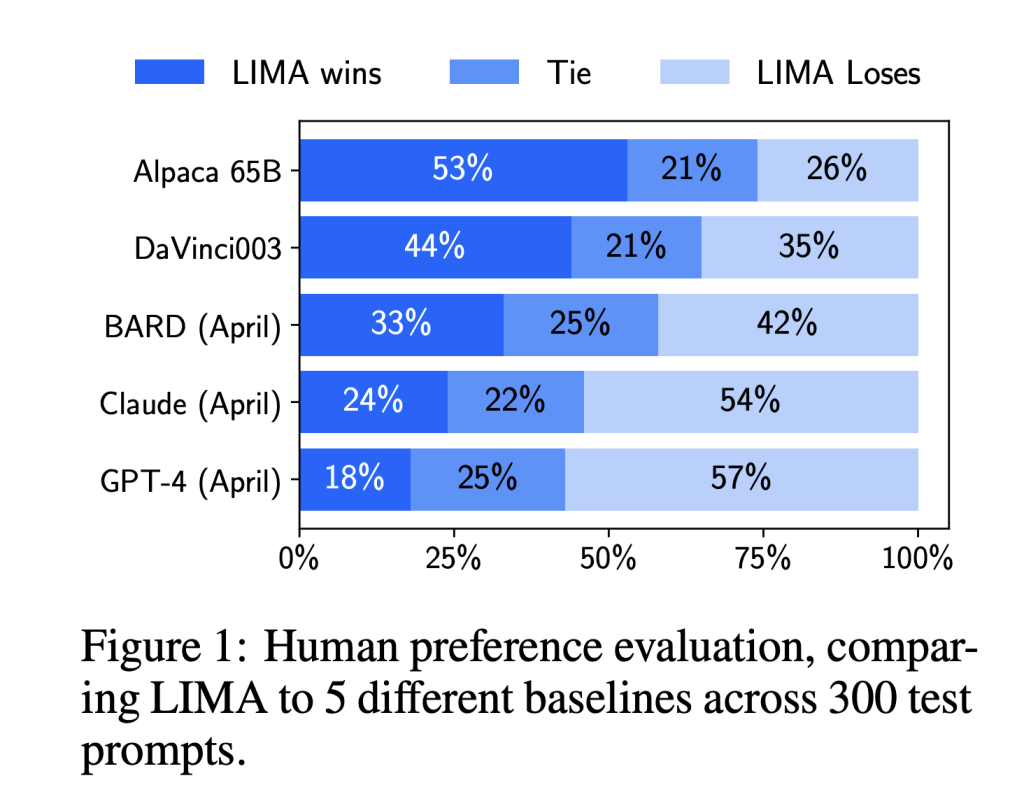
They also manually compose 250 instances of questions and answers while emphasizing a consistent response style in the vein of an AI assistant and optimizing for task diversity. Researchers from Meta AI, Carnegie Mellon University, University of Southern California and Tel Aviv University train LIMA, a 65B-parameter LLaMa model previously trained and improved on this collection of 1,000 examples. Three hundred difficult test questions compare LIMA against contemporary language models and products. LIMA surpasses RLHF-trained DaVinci003 from OpenAI, which was trained with RLHF, as well as a 65B-parameter replica of Alpaca, which was introduced on 52,000 samples, in a study of human preference.
Although humans frequently prefer GPT-4, Claude, and Bard replies over LIMA responses, this is not always the case; LIMA consistently yields equivalent or preferable results in 43%, 46%, and 58% of the situations, respectively. They repeat the annotations of human preferences using GPT-4 as the annotator confirms their findings. When LIMA replies are evaluated on an absolute scale, 88% satisfy the prompt’s requirements, and 50% are rated outstanding. Ablation tests show significant improvements when improving data quality and significantly falling returns when increasing data amount without simultaneously increasing prompt variety.
Furthermore, they discover that LIMA can carry on coherent multi-turn discourse despite having no dialogue examples. Including 30 hand-crafted dialogue chains in training may enhance this capacity. Overall, these amazing results show the effectiveness of pretraining and its relative value over approaches to reinforcement learning and large-scale instruction tailoring. They demonstrate how a robust pretrained language model may be tuned to provide outstanding, competitive outcomes on various prompts using 1,000 well-picked samples. There are, however, drawbacks to this strategy.
The mental work required to create such instances is enormous and challenging to scale up. Second, while LIMA normally provides strong replies, an unfortunate sample during decoding or an aggressive prompt can frequently result in a weak response. LIMA is less resilient than product-grade models. Nevertheless, the data provided in this work shows that it is possible to address the difficult alignment problems straightforwardly.
Check out the Pre-Print Paper. Don’t forget to join our 22k+ ML SubReddit, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more. If you have any questions regarding the above article or if we missed anything, feel free to email us at Asif@marktechpost.com
Check Out 100’s AI Tools in AI Tools Club
The post Meet LIMA: A New 65B Parameter LLaMa Model Fine-Tuned On 1000 Carefully Curated Prompts And Responses appeared first on MarkTechPost.