- info@i-genie.co.uk
- 0207 148 4785
In recent years, Significant progress has been made in music generation using Machine Learning models. However, there are still challenges in achieving efficiency and substantial control over the results. Previous attempts have encountered difficulties primarily due to limitations in music representations and model architectures.
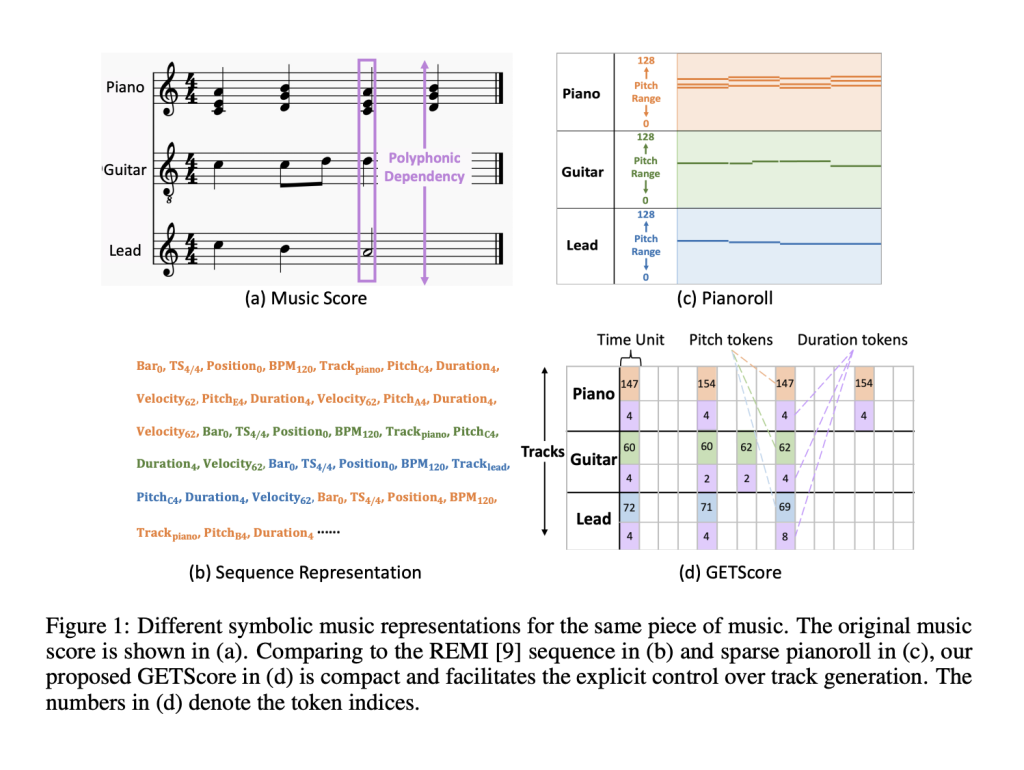
As there can be vast combinations of source and target tracks, there is a need for a unified model that can be capable of handling comprehensive track generation tasks and producing desired results. Current research in symbolic music generations can be generalized into two categories based on the adopted music representations. These are sequence-based and image-based. The sequence-based approach represents music as a sequence of discrete tokens, while the image-based approach represents music as 2D images having piano rolls as the ideal choice. Pianorolls represent music notes as horizontal lines, where the vertical position represents the pitch and the length of the line represents the duration.
To address the need for a unified model capable of generating arbitrary tracks, a team of researchers from China has developed a framework called GETMusic(GET stands for GEnerate music Tracks). GETMusic understands the input very well and can produce music by tracks. This framework allows users to create rhythms and add additional elements to make desired tracks. This framework is capable of creating music from scratch, and it can produce guided and mixed tracks.
Join the fastest growing ML Community on Reddit
GETMusic uses a representation called GETScore and a discrete diffusion model called GETDiff. GETScore represents tracks in a 2D structure where tracks are stacked vertically and progress horizontally with time. The researchers represented musical notes with a pitch and a duration token. The work of GETDiff is to select tracks as targets or sources randomly. GETDiff does two processes: The forward process and the Denoising process. In the forward process, the GETDiff corrupts the target track by masking tokens, leaving the source tracks preserved as ground truth. While in the denoising process, GETDiff learns to predict the masked target tokens based on the provided source.
The researchers highlight that this innovative framework provides explicit control over generating desired target tracks starting from scratch or based on user-provided source tracks. Additionally, GETScore stands out as a concise multi-track music representation, streamlining the model learning process and enabling harmonious music generation. Moreover, the pitch tokens utilized in this representation effectively retain polyphonic dependencies, fostering the creation of harmonically rich musical compositions.
In addition to its track-wise generation capabilities, the advanced mask and denoising mechanism of GETDiff empowers zero-shot infilling. This remarkable feature allows for the seamless denoising of masked tokens at any arbitrary positions within GETScore, pushing the boundaries of creativity and enhancing the overall versatility of the framework.
Overall GETMusic performs well, outperforming many other similar models, demonstrating superior melodic, rhythmic, and structural matching between the target tracks and the provided source tracks. In the future, the researchers are looking to explore the potential of this framework, with a particular focus on incorporating lyrics as an additional track. This integration aims to enable impressive lyric-to-melody generation capabilities, further advancing the versatility and expressive power of the model. Seamlessly combining textual and musical elements could open up new creative possibilities and enhance the overall musical experience.
Check out the Paper, Project, and Github. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 27k+ ML SubReddit, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
The post Meet GETMusic: A Unified Representation and Diffusion Framework that can Generate any Music Tracks with a Unified Representation and Diffusion Framework appeared first on MarkTechPost.