- info@i-genie.co.uk
- 0207 148 4785
Natural Language Processing has evolved significantly in recent years, especially with the creation of sophisticated language models. Almost all natural language tasks, including translation and reasoning, have seen notable advances in the performance of well-known models like GPT 3.5, GPT 4, BERT, PaLM, etc. A number of benchmarks are used to access and evaluate these developments in the field of Artificial Intelligence. Benchmark is basically a collection of standardized tasks made to test language models’ (LLMs’) abilities.
Considering the GLUE and the SuperGLUE benchmark, which were among the first few language understanding benchmarks, models like BERT and GPT-2 were more challenging as language models have been beating these benchmarks, sparking a race between the development of the models and the difficulty of the benchmarks. Scaling up the models by making them bigger and training them on bigger datasets is the key to enhanced performance. LLMs have demonstrated outstanding performance on a variety of benchmarks that gauge their capacity for knowledge and quantitative reasoning, but when these models score higher on the current standards, it is clear that these benchmarks are no longer useful for assessing the models’ capabilities.
To address the limitations, a team of researchers has proposed a new and unique benchmark called ARB (Advanced Reasoning Benchmark). ARB is made to convey more difficult issues in a variety of subject areas, such as mathematics, physics, biology, chemistry, and law. ARB, in contrast to earlier benchmarks, focuses on complex reasoning problems in an effort to improve LLM performance. The team has also introduced a set of math and physics questions as a subset of ARB that demand sophisticated symbolic thinking and in-depth subject knowledge. These issues are exceptionally difficult and outside the scope of LLMs as they exist today.
Join the fastest growing ML Community on Reddit
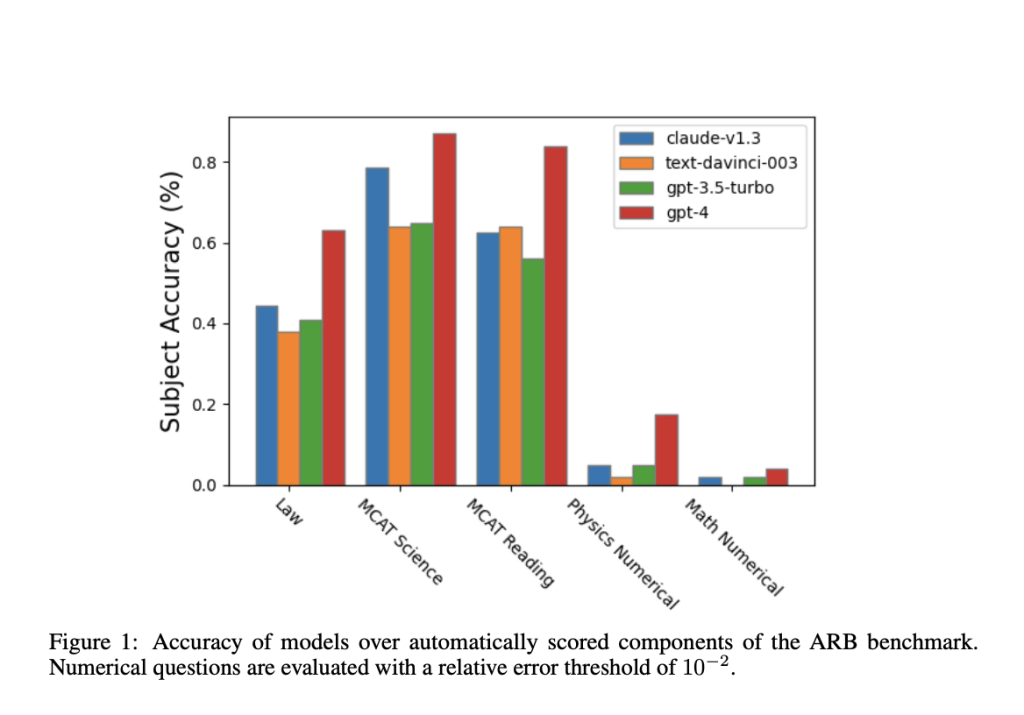
The team has evaluated these new models on the ARB benchmark, including GPT-4 and Claude. These models struggled to manage the complexity of these difficulties, as evidenced by the findings, which demonstrate that they perform on the more difficult tasks contained in ARB with scores significantly below 50%. The team has also demonstrated a rubric-based evaluation approach to improve the evaluation process. By using this strategy, GPT-4 may evaluate its own intermediate reasoning processes as it tries to solve ARB problems. This broadens the scope of the review process and sheds light on the model’s problem-solving strategy.
The symbolic subset of ARB has been subjected to human review as well. Human annotators have been asked to solve the problems and provide their own evaluations. There has been a promising agreement between the human evaluators and GPT-4’s rubric-based evaluation scores, suggesting that the model’s self-assessment aligns reasonably well with human judgment. With hundreds of issues requiring expert reasoning in quantitative fields, where LLMs have typically had difficulty, the new dataset significantly outperforms previous benchmarks.
In contrast to the multiple-choice questions in past benchmarks, a sizable number of the issues are made up of short-answer and open-response questions, making it harder for LLMs to be evaluated. A more accurate evaluation of the models’ capacities to handle complicated, real-world problems is made possible by the combination of expert-level reasoning tasks and more realistic question formats.
Check out the Paper, Github, and Project. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 27k+ ML SubReddit, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
We are releasing the Advanced Reasoning Benchmark dataset for LLMs (ARB)!– Evaluates SotA LLMs on ARB, on which even GPT4 struggles– Explores the feasibility of letting LLMs generate and use rubrics to evaluate generated solutions.proj: https://t.co/HdHYqSNZFW(1/N) pic.twitter.com/s8uCEssupD— DuckAI (@TheDuckAI) July 26, 2023
The post Meet Advanced Reasoning Benchmark (ARB): A New Benchmark To Evaluate Large Language Models appeared first on MarkTechPost.