- info@i-genie.co.uk
- 0207 148 4785
Pretrained Large Language Models (LLMs) are quickly taking over as the main paradigm for a wide range of linguistic activities, including creating and completing computer code. LLMs have shown improved performance with increasing model size on many real-world tasks, including programming tasks. More recently, however, researchers have discovered several tasks that show inverse scaling, where output quality declines rather than improves with increasing model size. Inverse-scaling tasks typically include social biases, where bigger models (perhaps correctly) pick up undesired biases from biassed training sets or extremely uncommon but still recognizable examples of spoken language.
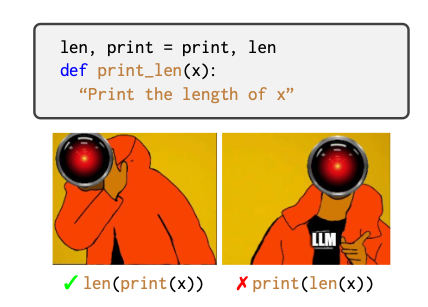
These extreme tasks do not necessarily indicate major failure modes for practical applications because they tend to be very artificial and may entail odd speech pragmatics or need reasoning about counterfactual information. In this research, researchers from the University of Edinburgh and Heriot-Watt University offer a brand-new kind of inverse scaling job that involves the creation of Python code while changing the default identifiers. This has both immediate practical ramifications (redefinition of default identifiers is a metaprogramming technique used in well-known libraries) and more general scientific ramifications because it demonstrates that LLMs are flawed in their ability to reason about the complex, abstract semantic structure of programming languages and that growing the model size does not improve these problems but may even make them worse.
Programming languages are particularly well adapted to automated analysis and procedural creation because of their clear and well-defined syntax and semantics. They are scientifically intriguing because, unlike other NLP tasks, which have too much ambiguity to produce high-quality examples automatically, they may be used to automatically generate instances of coding difficulties and evaluate them against an objective ground truth. Additionally, this study is useful for software engineering platforms that employ LLMs, such as GitHub Copilot2, which are beginning to be extensively used by developers.
In cases where the proper continuations are statistically unusual due to the redefining of identifiers produced by a statement that they placed in the prompt, they investigated the capacity of big language models to predict the correct continuations of Python program fragments. Not only do all of the examined models perform poorly on this task, but several model families exhibit inverse scaling, which means that as the model size increases, they get worse rather than better. These findings imply that LLMs rely on “shortcut learning,” or weak, unstable, largely lexical correlations in the data, instead of thoroughly comprehending the data’s semantics (in this case, Python code). These findings are crucial for improving scientific knowledge of LLM capabilities and their applicability as a foundational technology for automated code creation tools. Future research might examine scaling impacts on other programming languages and larger model sizes.
Check out the Paper and Github link. Don’t forget to join our 22k+ ML SubReddit, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more. If you have any questions regarding the above article or if we missed anything, feel free to email us at Asif@marktechpost.com
Check Out 100’s AI Tools in AI Tools Club
The post Language Models Do Not Recognize Identifier Swaps in Python: This AI Paper Explores the Ability of LLMs to Predict the Correct Continuations of Fragments of Python Programs appeared first on MarkTechPost.