- info@i-genie.co.uk
- 0207 148 4785
Recent advancements have enabled computers to interpret and understand visual information from the world, much like human vision. It involves processing, analyzing, and extracting meaningful information from images and videos. Computer Vision enables automation of tasks that require visual interpretation, reducing the need for manual intervention. Object detection is a computer vision task that involves identifying and locating multiple objects of interest within an image or a video frame.
Object detection aims to determine what objects are present in the scene and provide information about where they are located within the image. Most modern object detectors rely on manual annotations of regions and class labels, which limits their vocabulary size and makes it expensive to scale up further.
Vision-language models (VLM) can be used instead to bridge the gap between image-level pretraining and object-level finetuning. However, the notion of objects/regions needs to be adequately utilized in the pretraining process in such models.
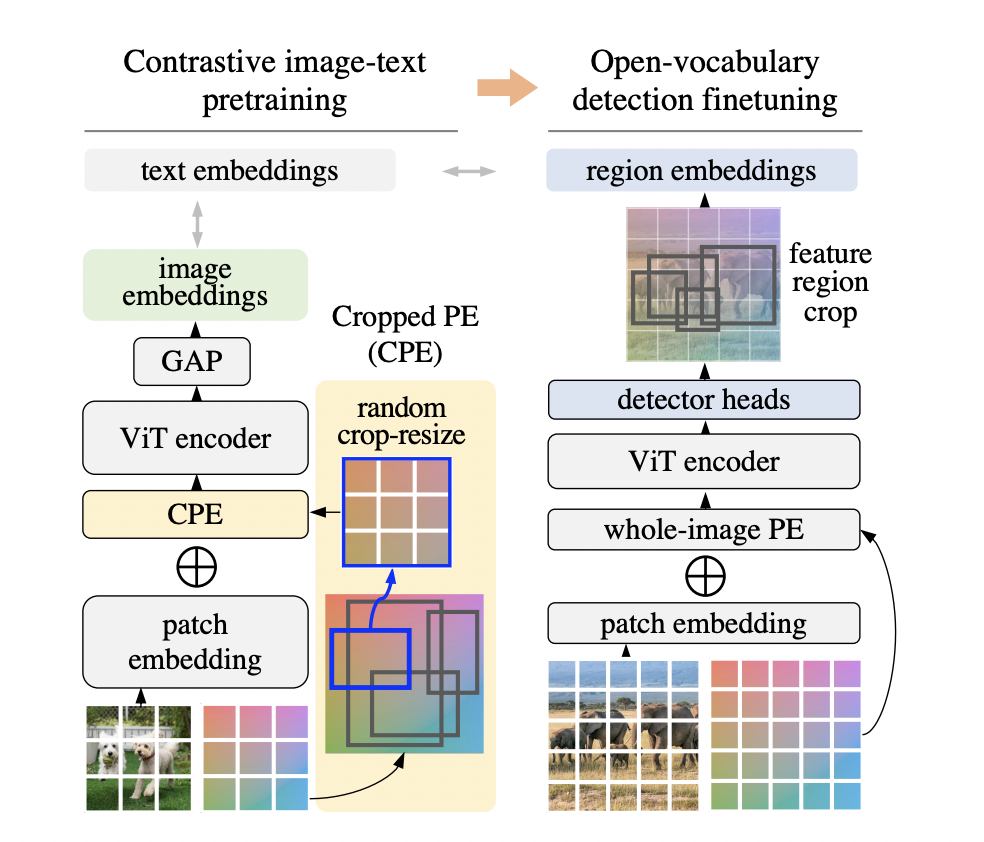
Researchers at Google Brain resent a simple model to build the gap between image-level pretraining and object-level finetuning. They present Region-aware Open-vocabulary Vision Transformers (RO-ViT) to complete the task.
RO-ViT is a simple way to pretrain vision transformers in a region-aware manner for open vocabulary object detection. Standard pretraining requires full image positional embeddings. Instead, researchers randomly crop and resize regions of positional embeddings instead of using the whole image’s positional embeddings. They call this method“ Cropped Positional Embedding.”
The team has shown that image-text pretraining with focal loss is more effective than existing softmax CE loss. They have also proposed various novel object detection techniques. They argue that existing approaches often miss novel objects in the object proposal stage because the proposals often need to be more balanced.
The team says their model RO-ViT achieves the state-of-the-art LVIS open-vocabulary detection benchmark. Their statistics say it archives it on 9 out of 12 metrics of image-text retrieval benchmarks. This reflects that the learned representation is beneficial at the regional level and highly effective in open-vocabulary detection.
As object detection technology advances, responsible development, deployment, and regulation will be crucial to ensuring that its positive impacts are maximized while mitigating potential risks. Overall, the continued progress in object detection technology is expected to contribute to a brighter future by revolutionizing industries, enhancing safety and quality of life, and enabling innovations that were once considered science fiction.
Check out the Paper and Google Blog. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 29k+ ML SubReddit, 40k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
The post Google Researchers Introduce RO-ViT: A Simple AI Method to Pre-Train Vision Transformers in a Region-Aware Manner to Improve Open-Vocabulary Detection appeared first on MarkTechPost.