- info@i-genie.co.uk
- 0207 148 4785
Large capacity models, such as Large Language Models (LLMs) and Large Multi-modal Models (LMMs), have demonstrated effectiveness across various domains and tasks. Scaling up these models by increasing parameter count enhances performance but significantly reduces inference speed, limiting practicality. Sparse Mixtures of Experts (SMoE) offer a promising alternative, enabling model scalability while mitigating computational costs. However, SMoE faces two key challenges: i) low expert activation and ii) limited analytical capabilities, which hinder its effectiveness and scalability.
SMoE enhances model capacity while maintaining constant computational demand, yielding superior performance compared to densely-activated models. Unlike dense models, SMoE employs N-independent Feed-Forward Networks (FFN) as experts within each Mixture-of-Experts (MoE) layer and a gating function to distribute weights over these experts’ outputs. The routing mechanism selects the top-k experts from N experts, where k << N facilitates data and expert parallelism. Larger k values often improve model performance but can reduce training efficiency.
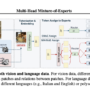
Researchers from Tsinghua University and Microsoft Research introduce Multi-Head Mixture-of-Experts (MH-MoE). MH-MoE utilises a multi-head mechanism to divide each input token into multiple sub-tokens and distribute them across different experts, achieving denser expert activation without increasing computational or parameter complexity. In contrast to SMoE, MH-MoE activates four experts for a single input token by splitting it into four sub-tokens. This allocation enables the model to focus on various representation spaces within experts, facilitating a more nuanced understanding of vision and language patterns.
The architecture of MH-MoE addresses issues of low expert activation and token ambiguity by employing a multi-head mechanism to split tokens into sub-tokens and route them to various experts. In MH-MoE, each parallel layer contains a set of N experts, with a multi-head layer projecting inputs followed by token splitting and gating functions to route sub-tokens to experts. The top-k routing mechanism activates experts with the highest scores, and the resulting sub-tokens are processed by these activated experts and rearranged before token merging to maintain input-output shape consistency. The Token-Splitting-Merging (TSM) operation increases the data volume routed to specific experts, resulting in denser expert activation and improved understanding. This process ensures no additional computational cost in subsequent blocks, with a hyperparameter β used to balance parameters and computational complexity with the original SMoE.
The validation perplexity curves for all pretrained models and pre-training tasks are examined under two expert settings (8 experts and 32 experts). MH-MoE consistently maintains lower perplexity than the baselines across various experimental setups, indicating more effective learning. Also, increasing the number of experts correlates with a decrease in perplexity for MH-MoE, suggesting enhanced representation learning capabilities. Downstream evaluation across different pre-training tasks further validates the efficacy of MH-MoE. In English-focused language modeling, MH-MoE achieves the best performance across multiple benchmarks, demonstrating its effectiveness in improving language representation. Similarly, MH-MoE outperforms X-MoE consistently in multi-lingual language modeling, showcasing its superiority in modeling cross-lingual natural language. In masked multi-modal modeling tasks such as visual question answering, visual reasoning, and image captioning, MH-MoE consistently outperforms Dense and X-MoE baselines, underscoring its ability to capture diverse semantic and detailed information within visual data.
In conclusion, This paper investigates methods for achieving denser expert activation without introducing additional cost while enhancing fine-grained understanding ability. The proposed MH-MoE offers a straightforward implementation of these functionalities. Also, MH-MoE’s simplicity facilitates seamless integration with other SMoE frameworks, improving performance easily. Extensive empirical results across three tasks validate the effectiveness of MH-MoE in achieving these objectives.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our Telegram Channel, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 40k+ ML SubReddit
The post Enhancing AI Model’s Scalability and Performance: A Study on Multi-Head Mixture-of-Experts appeared first on MarkTechPost.