- info@i-genie.co.uk
- 0207 148 4785
Given the potential for increased efficiency and broader accessibility, autonomous agents that can do ordinary tasks via human natural language instructions could considerably complement human skills. To fully use the potential of these independent agents, it is essential to comprehend their behavior in a genuine and reproducible setting.
Today’s settings tend to oversimplify complex problems. Therefore, many environments’ features are watered-down versions of real-world equivalents, resulting in a shortage of work variety. In other cases, the environment is presented as a static resource, limiting agents’ ability to explore only those states cached during data gathering.
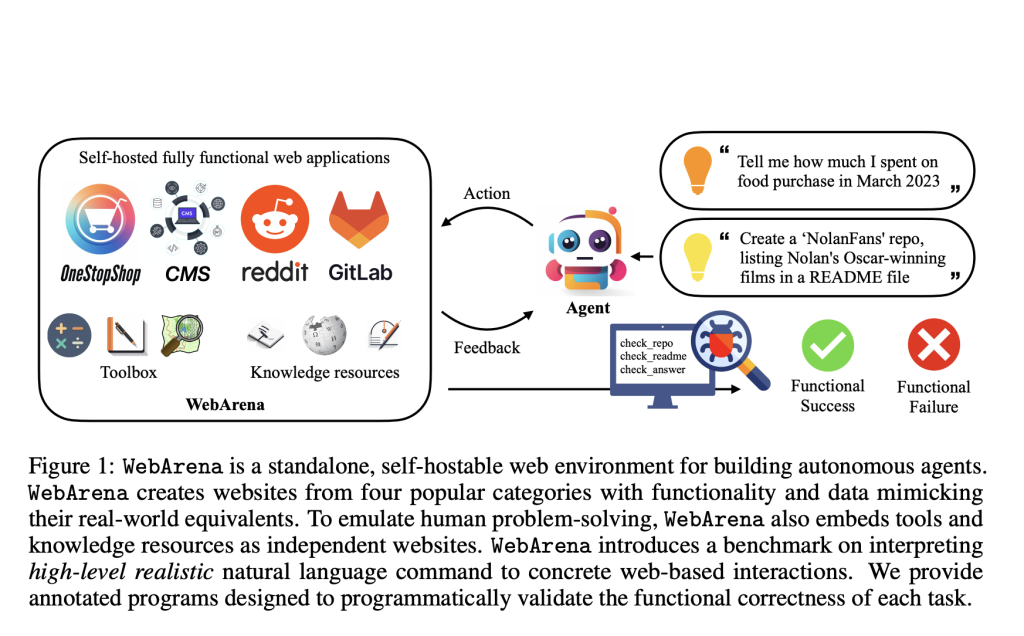
New research by Carnegie Mellon University and Inspired Cognition present WebArena, a simulated web environment with reproducible conditions that may be used to train autonomous agents to carry out certain tasks. The environment consists of four live, self-hosted web apps, one each for e-commerce, online discussion forums, collaborative software development, and enterprise content management. WebArena also includes several helpful tools, including a map, calculator, and scratchpad, to facilitate the most human-like task executions possible. Finally, WebArena is supported by a wealth of supplementary materials, including guides for using the integrated development environment and more specialized sites like the English Wikipedia. These websites’ content is culled directly from their offline counterparts, ensuring that it is accurate and up-to-date. Docker containers with gym APIs supply hosting services, making WebArena easy to use and replicable.
In addition to WebArena, they also open-source a fully operational benchmark of 812 future-oriented web-based tasks. Each activity is modeled after the abstract language usage patterns generally adopted by humans and described as a natural language aim. They focus on analyzing how well these functions work. In addition to being more accurate than comparing the plain action sequences, this assessment can account for the fact that there are sometimes multiple legitimate routes to the same goal (a universal situation in sufficiently complex tasks).
[ Trending ] Meet Pixis AI: An Emerging Startup Providing Codeless AI Solutions
The team utilizes this standard to compare the performance of numerous agents that can perform web-based operations in response to natural language commands. Many different methods are used to create these agents, from those that predict next steps based on current observations and history to those that use more complex methods like step-by-step reasoning. Powerful large language models (LLMs) like GPT-3.5 and GPT-4 create these agents in a few-shot in-context learning approach. The findings show that the best GPT-4 agent only managed an overall task success rate of 10.59 percent in the experiments. They hypothesize that current LLMs’ lack of key capabilities, including active exploration and failure recovery, is the root cause of their inability to effectively complete complicated tasks.
Check out the Paper, Project Page, and Github. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 26k+ ML SubReddit, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
The post CMU Researchers Introduce WebArena: A Realistic and Reproducible Web Environment with 4+ Real-World Web Apps for Benchmarking Useful Agents appeared first on MarkTechPost.