- info@i-genie.co.uk
- 0207 148 4785
Large Language Models (LLMs) have lately drawn a lot of interest because of their powerful text creation and comprehension abilities. These models have significant interactive capabilities and the potential to increase productivity as intelligent assistants by further aligning instructions with user intent. Native big language models, on the other hand, are limited to the realm of pure text and cannot handle other widely used modalities, such as pictures, audio, and videos, which severely restricts the range of applications for the models. A series of big Vision Language Models (LVLMs) have been created to improve big language models with the capacity to recognize and comprehend visual information to overcome this constraint.
These expansive vision-language models show considerable promise for resolving practical vision-central issues. Researchers from Alibaba group introduce the newest member of the open-sourced Qwen series, the Qwen-VL series models, to promote the growth of the multimodal open-source community. Large-scale visual-language models from the Qwen-VL family come in two flavors: Qwen-VL and Qwen-VL-Chat. The pre-trained model Qwen-VL connects a visual encoder to the Qwen-7B language model to provide visual capabilities. Qwen-VL can sense and comprehend visual information on multi-level scales after completing the three stages of training. Additionally, Qwen-VL-Chat is an interactive visual language model based on Qwen-VL that uses alignment methods and offers more flexible interaction, such as multiple picture inputs, multi-round discussion, and localization capability. This is seen in Fig. 1.
Figure 1: Some qualitative samples produced by the Qwen-VL-Chat are shown in Figure 1. Multiple picture inputs, round-robin conversations, multilingual conversations, and localization capabilities are all supported by Qwen-VL-Chat.
The characteristics of the
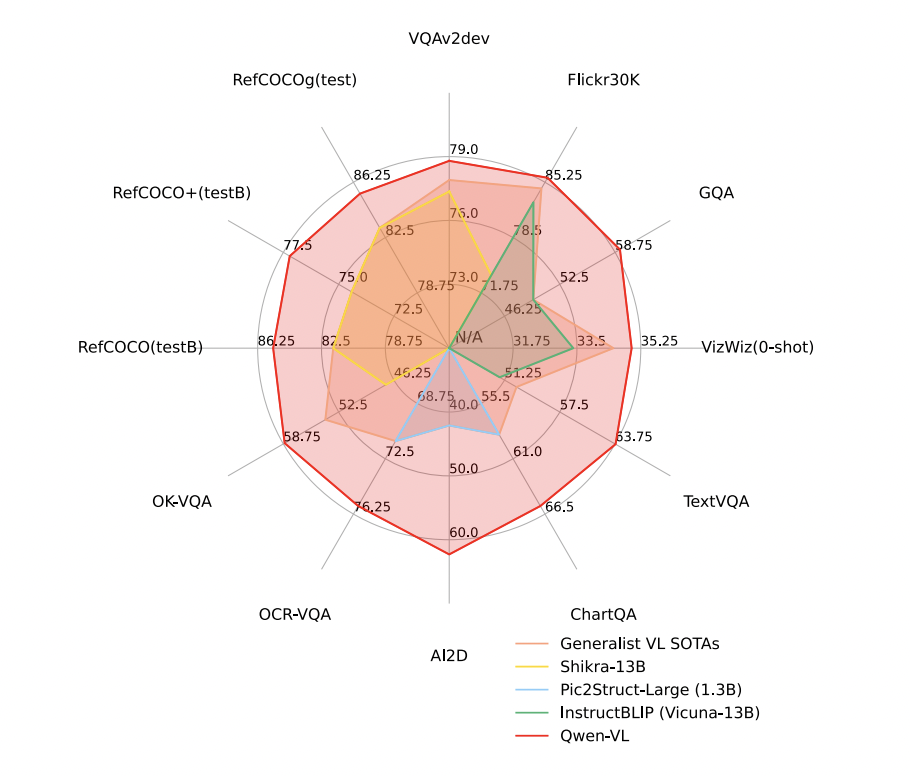
• Strong performance: It greatly outperforms current open-sourced Large Vision Language Models (LVLM) on several assessment benchmarks, including Zero-shot Captioning, VQA, DocVQA, and Grounding, at the same model level.
• Multilingual LVLM promoting end-to-end recognition and anchoring of Chinese and English bilingual text and instance in images: Qwen-VL naturally enables English, Chinese, and multilingual dialogue.
• Multi-image interleaved conversations: This feature enables comparing several pictures, specifying questions about the images, and participating in multi-image storytelling.
• Accurate recognition and comprehension: The 448×448 resolution encourages fine-grained text recognition, document quality assurance, and bounding box identification compared to the 224×224 resolution currently employed by competing open-source LVLM.
Check out the Paper and Github. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 29k+ ML SubReddit, 40k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
The post Alibaba Researchers Introduce the Qwen-VL Series: A Set of Large-Scale Vision-Language Models Designed to Perceive and Understand Both Text and Images appeared first on MarkTechPost.