- info@i-genie.co.uk
- 0207 148 4785
This paper addresses a novel approach called SyntHesIzed Prompts (SHIP) to improve existing fine-tuning methods.
Fine-tuning: After pre-training, the model is then fine-tuned on a smaller, task-specific dataset. This involves continuing the training process on the new data, often with a smaller learning rate. The idea is to tweak the generalized knowledge the model has gained from pre-training to make it more applicable to the specific task.
The problem the researchers are tackling is the scenario where some classes have no data. They aimed to train a generative model that can synthesize features by providing class names, which enables them to generate features for categories without data.
Join the fastest growing ML Community on Reddit
Generating features for categories without data refers to the process of synthesizing representations for classes or categories that are not present in the training dataset. This is particularly useful in scenarios where collecting real data for certain classes might be challenging or impossible.
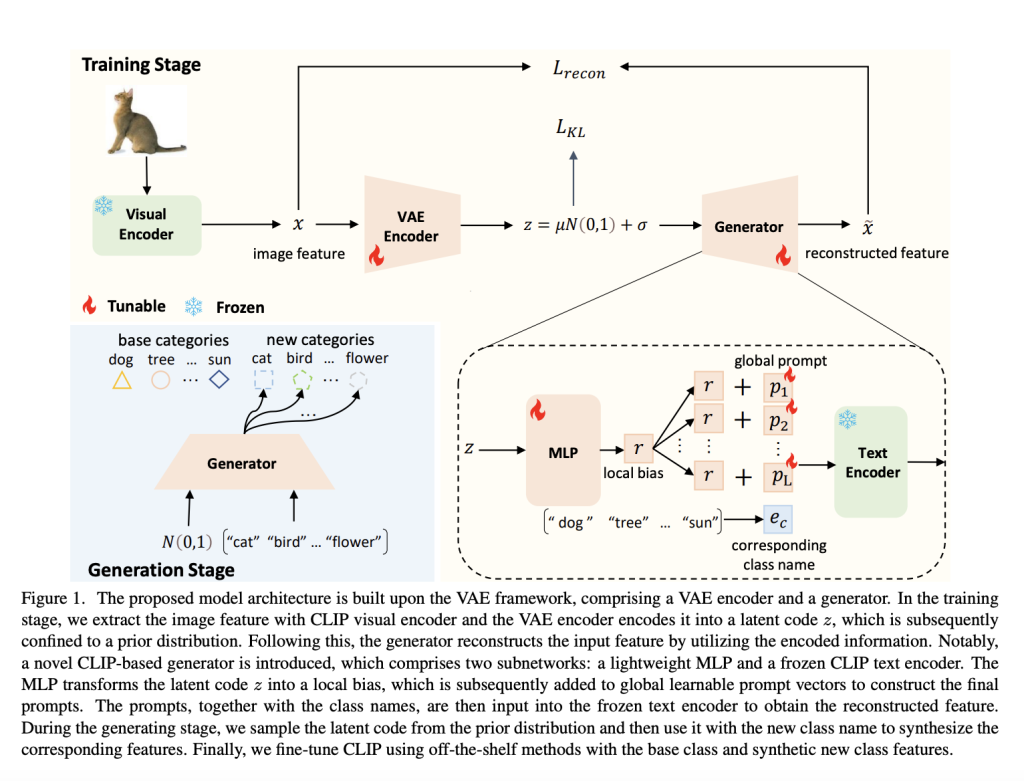
The researchers then fine-tuned CLIP using both the original labeled and the newly synthesized features with off-the-shelf methods. However, a major obstacle is that generative models typically require a substantial amount of data to train, which contradicts their goal of data efficiency. They proposed to utilize a variational autoencoder (VAE) as the framework, which is easier to train and more effective in low-data scenarios compared to models that require adversarial training.
While both GANs and VAEs are generative models capable of creating new data samples, they differ significantly in their architecture, objectives, and training methods. GANs are known for their ability to generate high-quality, realistic samples but can be challenging to train. VAEs, on the other hand, provide a probabilistic framework that can be easier to work with, especially in scenarios with limited data, but might not produce as sharp or realistic samples as GANs.
CLIP (Contrastive Language–Image Pretraining) is a model developed by OpenAI that learns to understand and generate images from textual descriptions and vice versa. It has been pretrained on a large-scale dataset and has aligned visual and language representations. The pretrained language encoder aids in generating more realistic features. The paper aims to enhance the performance of CLIP fine-tuning methods by utilizing synthesized data. They conducted comprehensive experiments on base-to-new generalization, cross-dataset transfer learning, and generalized zero-shot learning, resulting in state-of-the-art performance.
The proposed model architecture leverages the VAE framework to encode and generate features, integrating with CLIP to extract image features and reconstruct them. During training, the model learns to encode the features into a latent space and then reconstruct them. During the generating stage, it uses this learned encoding to synthesize features for new classes, allowing for fine-tuning of CLIP even when some classes have no data. The novel CLIP-based generator, comprising a lightweight MLP and a frozen CLIP text encoder, plays a key role in transforming the latent code and constructing the final prompts for feature reconstruction.
Experimental Results observed by the researchers:
Base-to-New Generalization: The experiments were conducted on 11 diverse image classification datasets, including ImageNet, Caltech101, OxfordPets, StanfordCars, Flowers102, Food101, FGVCAircraft, SUN397, DTD, EuroSAT, and UCF101. The datasets were partitioned into base classes and new classes, with training performed on base classes with 16 samples per class. The evaluation was done on both base and new classes.
Generalized Zero-Shot Setting: The paper also evaluated base-to-new generalization under a more realistic generalized zero-shot setting, where the base and new data are mixed together in the test dataset. The results indicated a significant decrease in performance for previous methods, but the proposed method, SHIP, continued to improve performance in new classes.
Comparison with Other Methods: The results were compared with other methods, including CLIP, CoOp, CLIP-Adapter, and Tip-Adapter. The proposed method, SHIP, showed improved performance in new classes across various datasets.
Conclusion:
The paper proposed a novel SyntHesIzed Prompts (SHIP) approach to improve existing fine-tuning methods, particularly in scenarios where some classes have no data. The method achieved state-of-the-art performance on various tasks by synthesizing features for categories without data and fine-tuning CLIP using both original labeled and newly synthesized features. The paper acknowledged additional training costs as a limitation and expressed an intention to explore the applicability of SHIP in dense prediction tasks in future research.
Overall, the paper presents a significant contribution to the field by addressing the challenge of data scarcity for certain classes and enhancing the performance of CLIP fine-tuning methods using synthesized data.
Check out the Paper. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 27k+ ML SubReddit, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
The post A New AI Research from China Proposes SHIP: A Plug-and-Play Generative AI Approach to Improve Existing Fine-Tuning Methods appeared first on MarkTechPost.